











"Dünyanın en büyük ücretsiz öğrenme platformuna hoş geldiniz!
Khan Academy eğitimde fırsat eşitliğini güçlendirmek için herkese, her yerde, dünya standartlarında ve ücretsiz bir öğrenim imkanı sağlamayı amaçlayan ve kar amacı gütmeyen uluslararası bir eğitim kuruluşudur. Tek bir şeyi bilmelisin: Her Şeyi Öğrenebilirsin! Şu anda Khan Academy Türkçe'nin resmi YouTube kanalındasınız, binlerce ders videosundan oluşan kütüphanemizi gezmek için web sitemizi ziyaret edebilirsiniz: www.khanacademy.org.tr #KhanAcademyTürkçe #DünyaOkulu #HerŞeyiÖğrenebilirsin #EğitimdeFırsatEşitliği #KhanAcademyTR * * * Khan Academy, bir STFA Vakfı olana Bilimsel ve Teknik Yayınları Çeviri Vakfı çatısı altında yüzlerce gönüllünün katkılarıyla Türkçeleştirilmektedir. Daha çok eğitim içeriğinin dilimize çevrilmesine ya da Khan Academy'nin ücretsiz bir kaynak olarak daha çok insana ulaşmasına destek olmak isterseniz, gönüllü olmak için bize ulaşın: info@khanacademy.org.tr"
behavioural interview
interview
Software Engineering

Answer: In my last project RiskMobile, we had performance and memory issues. We came up with some solutions for these :
Increased free heap memory space by up to %50 calculating report String size before transforming base64 StringBuilder.
Increased report photo upload speed by up to %80 using the parallel upload.
An increased report read time up to %80 by lazy loading.
Yazılım mühendisleri için davranışsal görüşme soruları (Behavioral Interviews: for Software Engineers)
Merhaba bu yazımda sizlere, teknik mülakattan önce işveren için adayı tanıma konusunda yol gösterici olan, davranışsal interview sorularına biraz kendi mesleki hayatımdan ve bazen kurgusal olarak örnekler vermeye çalışacağım.
Davranışsal görüşmede nasıl başarılı olunur?
1) Hazırlıksız gelme
Size hangi davranışsal mülakat sorularının sorulacağını önceden bilemezsiniz. Bununla birlikte, her zaman yaptığınız gibi yine de bir röportaj için hazırlanmanız gerekir. Aksi takdirde, mülakatı yapan kişide en iyi izlenimi bırakmadan kendi sözlerinizle ya da aklınıza gelen ilk şeyi söyleyerek mırıldanırsınız.
Şirketi araştırmaya ek olarak, büyük mesleki başarılarınızı ve zorluklarınızı hatırlamak için zaman ayırın. Hatta bunları bir yere yazabilirsiniz, böylece işe alma müdürü size başarılı ekip çalışması örneklerini sorarsa, zaten bir cevabınız oluşmuş olur.
2) STAR yaklaşımını kullanın
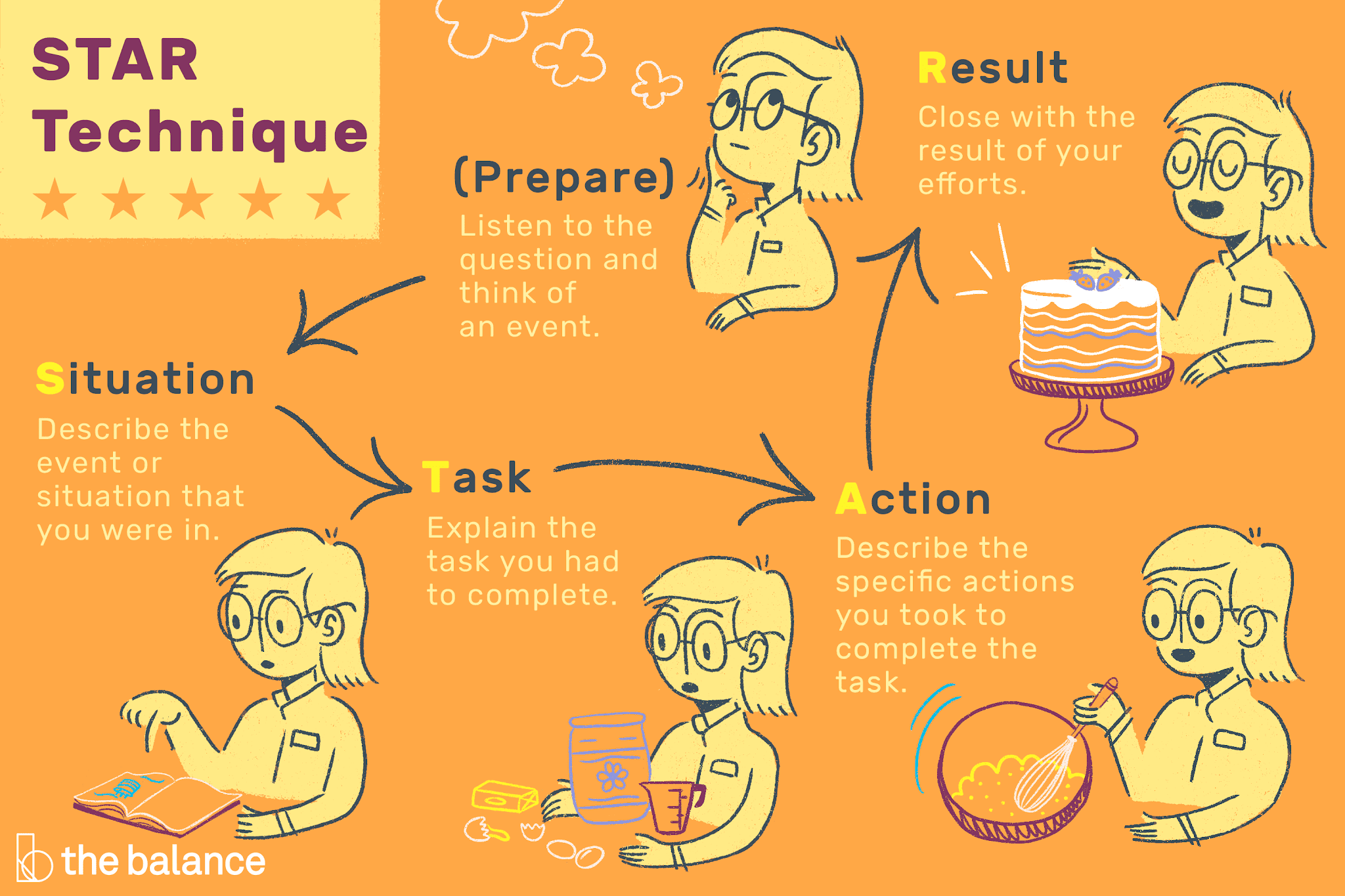
Kariyer danışmanları, STAR yaklaşımının davranışsal mülakat sorularına yanıt vermenin etkili bir yolu olduğunu belirtmektedir. Bilgilendirici ve kapsamlı bir cevap vermek için izlemeniz gereken belli bir yapıyı ifade eder.
- S (Situation) - durum - içinde çalışmanız gereken bağlamı ana hatlarıyla belirtin;
- T (Task) - görev - tamamlamanız gereken görevi, çözmeniz gereken sorunu veya belirlenen hedefi tanımlayın;
- A (Action) - eylem - yukarıda belirtilen görevi tamamlamak için gerçekleştirdiğiniz belirli eylemleri anlatın;
- R (Result) - sonuç - eylemlerinizle hangi sonucu başardığınızı açıklayın.
STAR tekniği neden işe yarıyor? Sadece konunun etrafında dolaşmadan odaklanmış bir cevap vermenize yardımcı olmakla kalmaz, aynı zamanda hedefe ulaşmak için hangi becerileri uyguladığınızı göstermenize de olanak tanır.
3) Rakamları ve gerçek olayları kullanın
STAR yaklaşımına göre hikayeyi anlatırken, onu kesin rakamlar ve belirli sonuçlarla enjekte edin. Ayrıca ünlü müşterinin veya sektörde etkili bir kişi olan patronun adını da bırakabilirsiniz. "Tanıttığım yeni yönetim tekniği ile zamandan tasarruf ettik" demek yerine, "Ekip görevleri% 10 daha hızlı tamamlamaya başladı" deyin. Gerçekler, sonuçlara odaklanmanızı ve güvenilir bir şekilde inşa ettiğinizi gösterir.
4) Kültürel uyumunuzu gösterin
Görüşme için hazırlanırken, web sitesini, sosyal medya sayfalarını ve orada çalışan kişilerin hikayelerini kullanarak şirketin kurumsal kültürünü araştırın. İşe alan kişinin sorularını yanıtlarken, mükemmel bir kültürel uyum olarak karşımıza çıkmak için farklı açılardan yararlanın. Örneğin, şirket bireyselliği ve rekabeti teşvik ediyorsa, stresi kendi katkınıza ve çabalarınıza koyun. Şirket ekip çalışmasına değer veriyorsa, içinde çalıştığınız ekibin başarısını gösteren hikayeleri anlatın.
5) Vücut diliniz üzerinde çalışın
Daha önce beden dilinin ve sözlü olmayan sinyallerin önemini duyduğunuzu biliyoruz. Ancak, tekrar edilmeye değer. Mesele şu ki, omuzlarınız devrilmiş ve bacak bacak üstüne atılmış olarak otururken kendinizi harika bir müzakereci ve en iyi performans gösteren biri olarak tanımlarsanız, görüşmeci tutarsız bir izlenim edinir. Bu yüzden mülakat anlaşması için ipuçları bile çok önemlidir.
Ünlü bir yaşam koçu Antony Robbins, daha güvenli görünmek ve hissetmek için "güçlü poz verme" yi öneriyor. Ofise girmeden önce, 2 dakika Süpermen gibi ellerinizi kalçalar üzerinde tutun. Bu pozu almak testosteron seviyenizi% 20 artırır ve stresi azaltır.
6) Negatif olmaktan kaçının
Görüşmenin yalnızca başarılarınızı kapsaması pek olası değildir. Görüşmeci, çatışmaları, zor durumlardaki çözümünüz ve başarısızlıkları nasıl ele aldığınızı görmek isteyecektir (bu arada, konuyla ilgili bazı uzman tavsiyelerini burada bulabilirsiniz: http://resumeperk.com/blog/conflicts-at-work-most-common-types), Dolayısıyla, muhtemelen müşteriden bir şikayet aldığınızda, projeyi zamanında teslim edemediğinizde veya iş için maliyetli olduğu ortaya çıkan bir hata yaptığınızda durum size sorulacaktır. "Asla hata yapmam" gibi bir şeye yanıt vermekten kaçının. Bu durumda hata yaptığınızı veya yanlış davrandığınızı kabul etmelisiniz, ancak durumdan öğrendiğiniz derslere odaklanmalısınız. Örneğin bilgi eksikliğinden dolayı bir hata yaptıysanız ileride bu tür hatalardan kaçınmak için kurumsal eğitim aldığınızı belirtebilirsiniz.
7) Önemsenecek noktalarınızı öğrenin ve bunları gösterin
Uzmanlar, ödevinizi yaparken sizi benzer niteliklere sahip adaylardan ayıran üç ana özelliği yazmanızı tavsiye ediyor. Örneğin, başkalarının tavsiye almak için başvuracağı bir kişi olmanız ya da pazarlama girişimleri sunan gerçekten yetenekli bir iletişimci olabilmeniz gibi.
Doğru soru ortaya çıktığında bu yetkinliklerden bahsedin. Davranışsal soruların doğru ya da yanlış cevapları olmadığından, düşüncelerinizi bir araya getirmek için birkaç saniyenizi ayırmanız sorun değildir (nefes alabilir veya biraz su yudumlayabilirsiniz).
Davranışsal sorular ve cevaplar ingilizce olacak, ayrıca Türkçe açıklama ve çeviriler eklenecektir.
01. Tell me about one of the most technically challenging projects you have done.
(Bitirmiş olduğunuz, teknik olarak en zorlu projelerden birini anlatın.)
Answer: Most of the projects that I was involved in were technically challenging. But if I had to choose one I would say Digital Agency Project in Anadolu Sigorta was the most challenging. When we started this project, the technologies we were using were just becoming popular in 2017 (Jhipster, Spring Boot, Angular 4, Elasticearch, Yarn, Liquebase, Mapstruct) and we didn't have too much knowledge about these technologies and we had to integrate them with Anadolu Sigorta SOA services. The project domain was also complex.
02. Tell me about one of your failed projects. What did you learn? What could you do differently?
(Bana başarısız projelerinizden birini anlatın. Ne öğrendin? Neyi farklı yapabilirdin?)
Answer: I can give an example of a big task of a project where things didn't go exactly the way I wanted. In Garanti Investment web project financial dictionary implementation was an important part of the project. I was not as well skilled at javascript as backend technologies. And I didn't have a lot of knowledge of clean code nor was I aware of its importance. I successfully finished the dictionary implementation, but it took too long and it hadn't been implemented with clean code principles and effective way. Our team leader decided to implement it from the scratch by himself.
After that completion of the task, I realized the importance of clean code and writing effective javascript code.
03. Tell me about the project that you are most proud of. What was the most significant accomplishment of your entire career?
(Bana en çok gurur duyduğun projeden bahset. Tüm kariyerinizin en önemli başarısı neydi?)
Answer: If had to choose one I would say the project I am most proud of was emlakjet.com rebuilding project. We analysed the legacy project, understood the domain, migrated the database from MySQL to PostgreSQL, implemented the project with the modern framework, and completed the project successfully before the deadline.
04. Tell me about a time that you found a creative solution to a problem.
(Bana bir soruna yaratıcı bir çözüm bulduğunuz zamanı anlatın.)Answer: In my last project RiskMobile, we had performance and memory issues. We came up with some solutions for these :
Increased free heap memory space by up to %50 calculating report String size before transforming base64 StringBuilder.
Increased report photo upload speed by up to %80 using the parallel upload.
An increased report read time up to %80 by lazy loading.
05. Tell me about a time when you had a conflict with your teammate or manager: how did you resolve it, and what did you learn?
(Takım arkadaşın veya yöneticinle bir çatışma yaşadığın bir zamandan bahset: Bunu nasıl çözdün ve ne öğrendin?)
Answer: Usually, conflicts happen between analysts and developers. In such cases, I have a private conversation with the analyst to try to understand him/her and tell him/her about my task-related dilemmas. I try to find a solution together without making it a personal issue.
06. Tell me about a time that you were behind on a project and you knew that you could not meet the deadline. Tell me about a time when you changed priorities to meet a deadline.
(Bana bir projede geride kaldığınız ve son teslim tarihine yetişemeyeceğinizi bildiğiniz bir zamandan bahsedin. Son teslim tarihine uymak için önceliklerinizi değiştirdiğiniz bir zamandan bahsedin.)
Answer: In a new version of the Alcatel OSOS project, we had defects to solve and new features to add. Towards the end date, we were far behind these goals. We have postponed less critical new features to the next version and put it first to solve problems that matter to the customer. After solving the problems, we applied the most valuable new features and successfully released the version.
07. Tell me about a time that you had to implement a workaround (vs. a solution) for a critical issue to meet a deadline and as a result, you introduced technical debt. What did you do with the technical debt after the deadline?
(Son teslim tarihini karşılamak için kritik bir sorun için bir geçici çözüm (çözüm yerine) uygulamak zorunda olduğunuz ve bunun sonucunda teknik borç getirdiğiniz bir zamandan bahsedin. Son teslim tarihinden sonra teknik borcunuzla ne yaptınız?)
Answer:We are developing a complex feature for an e-commerce platform - an advanced search system that uses machine learning algorithms to predict and suggest user interests.
A few days before the deadline, we discover a significant issue. The machne learning model isn't training correctly, and resolving the problem would require considerable time for debugging, retraining, and validation - time we don't have.
With the deadline fast approaching, we decide to implement a workaround: instead of using the machine learning model, we develop a simpler rule-based system for the search feature. While it's not as accurate or efficient, it serves the purpose for the time being, and we manage to ship the feature on time. However, this creates technical debt in our codebase - we now have a less optimal feature that will need to be upgraded in the future.
After the deadline has passed, we don't ignore the technical debt we've accrued. We understand that while the workaround was necessary at the time, it's not a sustainable or long-term solution. We discuss the matter with the project manager and propose a plan to repay this debt. The plan includes:
Identifying the Problem: We document the details of the technical debt, its cause, and what parts of the system it affects.
Planning the Solution: We design a strategy for fixing the ML model issue. This involves debugging the problem, implementing the fix, retraining the model, and validating its results.
Scheduling: We plan out a timeline for the work, considering other project requirements and deadlines.
Implementation: We work on the issue according to the schedule, replacing the rule-based system with the intended machine learning model.
Testing and Verification: We rigorously test the new system to ensure it works as expected and improves upon the old system.
Documentation: We update all relevant documentation to reflect the changes made and document the lessons learned to prevent a similar occurrence in the future.0
8. Why do you want to leave your current job? Could you mention some general issues in your current job? Have you taken any action to mitigate/resolve those issues?
(Mevcut işinizden neden ayrılmak istiyorsunuz? Şu anki işinizle ilgili bazı genel sorunlardan bahsedebilir misiniz? Bu sorunları hafifletmek / çözmek için herhangi bir önlem aldınız mı?)
Answer:"I have had a rewarding journey at my current company and I've learned a lot, but I believe it's time for me to take on new challenges and further develop my skill set. There are a few reasons behind my decision to look for a new opportunity.
One ofthe main issues has been the limited opportunities for growth and advancement in my current role. I have a deep interest in working with emerging technologies like artificial intelligence and machine learning, but my current job does not provide the space to explore these areas. I value continuous learning and professional development, and unfortunately, it's been challenging to find those opportunities in my current role.
Another factor has been the lack of balance between work and personal life. I understand that there will be times when extra hours are necessary, especially in software development, but it has become a consistent trend rather than the exception. This has, in turn, affected my work-life balance.
I've certainly taken steps to address these issues. Regarding the growth opportunities, I've tried to incorporate learning into my personal time and have taken online courses to stay abreast with the latest technologies. However, this doesn't provide the same benefits as practical, on-the-job experience would.
In terms of the work-life balance issue, I've had open discussions with my team lead and manager about it. We've tried to distribute workload more evenly and hire additional team members to manage the workload. But the pace of the company and the resource constraints have made it difficult to bring about substantial change.
Given these circumstances, I believe it would be beneficial for my career and personal growth to explore new opportunities where I can leverage my skills and passion for emerging technologies, while also maintaining a healthier work-life balance. I'm excited about the opportunities that your company provides in both these aspects."
09. Why do you want to join us? What do you know about our company?
(Neden bize katılmak istiyorsun? Şirketimiz hakkında ne biliyorsun?)
Answer: "I'm really impressed with your company's reputation for innovation and commitment to using the latest technologies to create impactful products. As an engineer passionate about working with cutting-edge technology, it's exciting to see the breadth of projects your team takes on.
Your company's focus on artificial intelligence and machine learning, for instance, is particularly appealing to me. In my previous role, I didn't get much opportunity to explore these areas, and I'm eager to dive into this field. I've taken some online courses and done personal projects, but working with your team would provide a more in-depth, practical experience that I am looking for.
I've also read about your company's emphasis on maintaining a healthy work-life balance for your employees. This aligns with my personal values and my belief in the importance of a balanced lifestyle for productivity and creativity.
I'm also aware of your company's strong commitment to giving back to the community, which I find admirable. I appreciate that you go beyond just doing business and strive to make a positive impact in society.
Furthermore, your company culture, which encourages collaboration, continuous learning, and innovation, is very appealing. I believe this kind of environment will help me grow as a professional and contribute more effectively to the team.
In summary, I want to join your company because I believe it aligns with both my professional goals and personal values. I'm excited about the prospect of contributing to and learning from a team that's pushing boundaries in technology, all while maintaining a sustainable work-life balance and making a positive impact on the community."
10. If you have worked in many companies for short periods of time (< 2yrs), why do you switch your jobs so frequently?
(Kısa süreler için (<2 yıl) birçok şirkette çalıştıysanız, neden işlerinizi bu kadar sık değiştiriyorsunuz?)
Answer:"I appreciate your concern about the frequency of job changes in my history. I believe it's crucial to clarify that these changes were not made lightly, but were carefully considered steps in my career progression.
Early in my career, I had the opportunity to work in different start-ups, each offering unique projects and technologies. These opportunities allowed me to broaden my skill set and understand various facets of software engineering. My goal was to gain diverse experience in a relatively short amount of time, and these roles offered me the chance to do just that.
In a couple of instances, the startups I was working for underwent significant changes, such as acquisition or restructuring, which led to my decision to move on sooner than anticipated.
While it may seem that I've moved jobs frequently, each move was a strategic decision to broaden my knowledge base, increase my experience with different technologies and industries, and adapt to unforeseen circumstances.
I've always made sure to leave on good terms, having delivered significant contributions and after ensuring a smooth transition. I believe the varied experiences have made me more adaptable, versatile, and capable as a software engineer.
Having said that, I am now looking for a longer-term opportunity where I can grow deeper roots, continue to learn and contribute significantly. Your company, with its innovative projects and stability, seems like an excellent fit for this next phase of my career."
11. What is your weakness?
(Zayıf yönün nedir?)
Answer:"I think one of my weaknesses has been overcommitting myself. I am very passionate about my work and I tend to get excited about new projects or challenges, so sometimes I take on more tasks than I should. This can lead to longer hours and increased stress levels as I strive to deliver on all my commitments.
However, I've been working actively to improve in this area. I've started using project management tools and techniques to better manage my workload, and I'm becoming more conscious about the commitments I take on. I've also been learning to delegate effectively and have open discussions with my team and superiors about workload distribution and deadlines.
Recognizing this weakness has been a valuable realization for me, and while I am still a work in progress, I am committed to continuing to improve my time management and workload balancing skills. This self-improvement will not only increase my productivity but also maintain the quality of work I am known for."
12. What is your strength?
(Güçlü yönün nedir?)
Answer: I believe that my greatest strength is the ability to solve problems quickly and efficiently. I can see any given situation from multiple perspectives, which makes me uniquely qualified to complete my work even under challenging conditions. That problem solving allows me to be a better communicator. I am just as comfortable speaking to senior executives as I am junior team members. I think my ability to see all sides of an issue will make me a great asset to the team.
13. What is your current salary, or what is your salary expectation?
(Mevcut maaşınız veya maaş beklentiniz nedir?)
Answer:
14. What does your typical day look like at your current job?
(Mevcut işinizde tipik bir gününüzü nasıl geçirirsiniz?)
Answer:
15. Describe one of the biggest mistakes you have made in your job, and what did you learn?
(İşinizde yaptığınız en büyük hatalardan birini anlatın ve bu hatadan ne öğrendinizi söyleyin?)
Answer:
16. Describe a situation in which you were faced with a major obstacle in order to complete a project. How did you deal with it? What steps did you take?
(Bir projeyi tamamlamak için büyük bir engelle karşı karşıya kaldığınız bir durumu anlatın. Bununla nasıl başa çıktın? Hangi adımları attın?)
Answer:
17. How do you solve ambiguous problems?
(Belirsiz sorunları nasıl çözersiniz?)
Answer:
18. How do you see yourself in five (or ten) years? What skills do you want to learn?
(Kendinizi beş (veya on) yılda nasıl görüyorsunuz? Hangi becerileri öğrenmek istiyorsun?)
Answer: In several years, I see myself involved in architecting complex Java applications. Beyond that is too far away to think of right now.
19. Tell me about a time that you supervised/trained other engineers.
(Bana diğer mühendisleri denetlediğiniz / eğittiğiniz bir zamandan bahsedin.)
Answer:
20. Tell me about a time that you changed or improved the culture of your company or team.
(Şirketinizin veya ekibinizin kültürünü değiştirdiğiniz veya geliştirdiğiniz bir zamandan bahsedin.)
Answer:
21. Tell me about a time that you took the initiative.
(Bana inisiyatif aldığınız bir zamandan bahsedin.)
Answer:
22. Do you read any related blogs?
(İlgili herhangi bir blog okuyor musunuz?)
Answer:
23. Describe a time when you made a suggestion to improve something within the project that you were working on.
(Üzerinde çalıştığınız proje içinde bir şeyi iyileştirmek için bir öneride bulunduğunuz bir zamanı anlatın.)
Answer:
24. Give me an example of a time when you noticed a small problem before it turned into a major one. Did you take the initiative to correct it? What kind of preventive measures did you undertake?
(Küçük bir problemi büyük bir problem haline gelmeden önce fark ettiğiniz bir zamana örnek verin. Düzeltmek için inisiyatif aldınız mı? Ne tür önleyici tedbirler aldınız?)
Answer:
25. How will you adjust yourself in a fast-paced environment?
(Hızlı tempolu bir ortamda kendinizi nasıl ayarlarsınız?)
Answer:
26. What is your learning process like? How do you learn new skills?
(Öğrenme süreciniz nasıl? Yeni becerileri nasıl öğrenirsiniz?)
Answer:
27. What don’t you like in a job?
(Bir işte neyi sevmezsin?)
Answer:
28. When do you consider a project to be successful?
(Bir projenin ne zaman başarılı olduğunu düşünürsünüz?)
Answer:
29.Tell me about a time when you had to present a complex programming problem to a person that didn’t understand technical jargon. How did you ensure that the other person understood you?
(Bana teknik jargonu anlamayan bir kişiye karmaşık bir programlama problemi sunmanız gereken bir zamandan bahsedin. Diğer kişinin sizi anladığından nasıl emin oldunuz?)
Answer:
30.Tell me about a time you had to work on several projects at once. How did you handle that?
(Aynı anda birkaç proje üzerinde çalışmanız gereken bir zamandan bahsedin. Bunu nasıl hallettiniz?)
Answer:
31.Describe a situation in which you have experienced a significant project change that you weren’t expecting. What was it? How did that impact you, and how did you adapt to this change? How did you remain productive through the project?
( Beklemediğiniz önemli bir proje değişikliği yaşadığınız bir durumu açıklayın. Bu neydi? Bu sizi nasıl etkiledi ve bu değişime nasıl uyum sağladınız? Proje boyunca nasıl üretken kaldınız?)
Answer:
32.Tell me about a time when you had to work with a difficult person to accomplish a goal. What was the biggest challenge? How did you handle it?
(Bir hedefe ulaşmak için zor bir insanla çalışmanız gereken bir zamandan bahsedin. En büyük zorluk neydi? Bunu nasıl hallettin?)
Answer:
Kaynaklar : CRACKING THE BEHAVIORAL INTERVIEWS FOR SOFTWARE ENGINEERS, FIRST EDITION , https://devskiller.com/45-behavioral-questions-to-use-during-non-technical-interview-with-developers/ , https://resumeperk.com/blog/behavioral-interview-questions---and-how-to-answer-them
DDD
Software Architecture
Software Engineering
Strategic DDD
1- Strategic Domain-Driven Design - vaadin.com - Petter Holmström - Çevirsi
"Bu makale dizisinde, Domain Driven Desgin (domaine dayalı tasarım)'ın ne olduğunu ve projenize - veya bir kısmının - projelerinize nasıl uygulanacağını öğreneceksiniz." diyor Petter Holmström. Ben de elimden geldiğince bu yazı dizisini Türkçe'ye çevirmeye çalışacağım. Umarım İngilizce okumada zorluk çeken arkadaşlar için yararlı olur.
Yazı Dizisinin Orjinali
Örnek DDD projesi
Serinin diğer yazıları :
2 - Tactical Domain Driven Design (Taktiksel DDD)
3 - Domain-Driven Design and the Hexagonal Architecture (DDD ve Altıgen Mimari)




Conformist (Uyumlu Kimse)
Yazı Dizisinin Orjinali
Örnek DDD projesi
Serinin diğer yazıları :
2 - Tactical Domain Driven Design (Taktiksel DDD)
3 - Domain-Driven Design and the Hexagonal Architecture (DDD ve Altıgen Mimari)
1 - Strategic Domain-Driven Design
(Stratejik DDD)
Domaine Dayalı Tasarım (DDD) Eric Evans'ın konuyla ilgili kitabını 2003'te yayınladığından beri var. Birkaç yıl önce veri tutarlılığı sorunları olan bir projeye katıldığımda DDD ile haşır neşir oldum. Veritabanında tekrarlanan veriler ortaya çıktı, bazı bilgiler hiç kaydedilmedi ve her yerde ve her zaman iyimser kilitleme hatalarıyla karşılaşabileceğimi gördüm. Taktiksel DDD tasarımın yapı taşlarını kullanarak bunu çözmeyi başardık.O zamandan beri Domaine Dayalı Tasarım (DDD) hakkında daha fazla şey öğrendim ve bunu projelerimde uygun olan yerlerde kullanmaya çalıştım. Bununla birlikte, diğer geliştiricilerle konuştuğum geçtiğimiz yıllarda, birçoğu domaine dayalı tasarım terimini duydu, ancak bunun ne anlama geldiğini bilmiyorlar. Bu makale dizisinde, gördüğüm ve anladığım şekliyle Domaine Dayalı Tasarım (DDD) a kısa bir giriş yapacağım. İçerik büyük ölçüde Eric Evans'ın Domain-Driven Design: Tackling Complexity in the Heart of Software ve Implementing Domain-Driven Design kitaplarına dayanıyor. Ancak her şeyi kendi sözlerimle açıklamaya ve kendi düşüncelerimi, görüşlerimi ve deneyimlerimi de aşılamaya çalıştım.
Makale dizimi okuyarak Domaine Dayalı Tasarım (DDD) konusunda uzman olmayacaksınız, ancak umarım bu konu hakkında daha fazlasını başka yerlerde okumanız için size ilham verir. Ayrıca Evans ve Vernon'un kitaplarını okumanızı şiddetle tavsiye ediyorum.
Şimdi ilk konuya, yani stratejik Domaine Dayalı Tasarım (DDD) 'a başlayalım.
Domain(Etki Alanı) nedir?
MacBook'umdaki Sözlük uygulamasında domain'in kelime ararsam aşağıdaki tanımı alırım:
[A] n belirli bir hükümdar veya hükümetin sahip olduğu veya kontrol ettiği bölge bölgesi…
- belirli bir faaliyet veya bilgi alanı ...
- Apple Sözlüğü
Domaine Dayalı Tasarım (DDD) söz konusu olduğunda, bizim ilgilendiğimiz tanımın ikinci kısmıdır. Bu durumda, faaliyet bir organizasyonun yaptığı şeydir ve bilgi, organizasyonun nasıl yaptığıdır. Alan konseptine organizasyonun faaliyetlerini yürüttüğü ortamı da ekleyeceğiz.
Subdomains (Alt alanlar)
Alan kavramı çok geniş ve soyuttur. Daha somut ve elle tutulur hale getirmek için, onu alt alan adı verilen daha küçük parçalara ayırmak mantıklıdır. Bu alt domainleri bulmak her zaman kolay bir şey değildir ve eğer yanlış yaparsanız, bulmacanızdaki parçalar birden bire birbirine tam oturmadığında yolun yarısında sorun yaşayabilirsiniz.
Alt domainleri aramaya başlamadan önce, alt domain kategorileri hakkında düşünmelisiniz. Tüm alt alanlar üç kategoriye ayrılabilir:
- Çekirdek alanlar (Core Domains)
- Destekleyen alt alanlar (Supporting Subdomains)
- Genel alt alanlar (Generic Subdomains)
Bu kategoriler yalnızca alt alan adlarınızı bulmanıza yardımcı olmakla kalmaz, aynı zamanda geliştirme çabalarınızı önceliklendirmenize de yardımcı olur.
Bir organizasyona özel ve diğer organizsasyonlardan farklı kılan şey çekirdek alan adıdır. (core domain) Bir organizsayon, core domnainde olağanüstü derecede iyi olmadan başarılı olamaz (hatta var olamaz). Core domain çok önemli olduğu için, en yüksek önceliği, en büyük çabayı ve en iyi geliştiricileri alması gerekir. Daha küçük alanlar için yalnızca tek bir core domain tanımlayabilirsiniz, daha büyük alanların birden fazla alanı olabilir. Core domain'in özelliklerini sıfırdan oluşturmaya hazırlıklı olmalısınız.
Destekleyen bir alt alan (Supporting Subdomains), kuruluşun başarılı olması için gerekli olan, ancak core domain kategorisine girmeyen bir alt alan adıdır. Genel değildir çünkü söz konusu organizasyon için hala bir miktar uzmanlaşma gerektirir. Mevcut bir çözümle başlayabilir ve onu ince ayarlayabilir veya özel ihtiyaçlarınıza göre genişletebilirsiniz.
Genel bir alt alan adı (Generic Subdomains), kuruluşa özel herhangi bir şey içermeyen ancak yine de genel çözümün çalışması için gerekli olan bir alt alan adıdır. Genel alt alan adlarınız için hazır yazılımları kullanmaya çalışarak zamandan ve işten tasarruf edebilirsiniz. Tipik bir örnek, kullanıcı kimliği yönetimi olabilir.
Organizsayonun ne yaptığına bağlı olarak aynı alt alan adının farklı kategorilere girebileceğini belirtmek gerekir. Kimlik yönetimi konusunda uzmanlaşmış bir şirket için kimlik yönetimi core bir alandır. Bununla birlikte, müşteri ilişkileri yönetimi konusunda uzmanlaşmış bir şirket için kimlik yönetimi, generic bir alt alan adıdır.
Son olarak, tüm alt alan adlarının, hangi kategoriye girdiklerine bakılmaksızın genel çözüm için önemli olduğuna dikkat çekmek önemlidir. Bununla birlikte, farklı miktarlarda çaba gerektirirler ve aynı zamanda farklı kalite ve eksiksizlik gereksinimlerine sahip olabilirler.
Misal
Küçük klinikler için bir EMR (Elektronik Tıbbi Kayıtlar) sistemi oluşturduğumuzu varsayalım. Aşağıdaki alt alanları belirledik:
- Hasta tıbbi kayıtlarını yönetmek için Hasta Kayıtları(Patient Records) (kişisel bilgiler, tıbbi geçmiş, vb.).
- Laboratuvar testleri sipariş etmek ve test sonuçlarını yönetmek için laboratuar(Lab).
- Randevuları planlamak için planlama(Scheduling ).
- Hasta kayıtlarına (farklı belgeler, röntgen resimleri, taranmış kağıt belgeler gibi) eklenmiş dosyaları depolamak ve yönetmek için Dosya Arşivi (File Archive).
- Doğru kişilerin doğru bilgilere erişimini sağlamak için Kimlik Yönetimi (Identity Management).
Şimdi, bu alt alanları nasıl sınıflandırabiliriz? En bariz olanlar, açıkça genel alt alanlar olan dosya arşivi ve kimlik yönetimidir. Peki ya diğerleri? Bu, bu özel EMR sistemini piyasadaki diğerleri arasında öne çıkaran şeyin ne olduğuna bağlıdır.

Bir EMR sistemi kurduğumuz için, hasta kayıtlarının temel bir alan olduğunu varsaymak oldukça güvenlidir. Akıllı ve yenilikçi zamanlama yoluyla tüm kliniklerin daha verimli çalışmasını sağlayan bir sistem oluşturarak pazarı ele alacaksak, o zaman planlama da muhtemelen core bir alandır. Aksi takdirde, supporting bir alt domaindir, belki mevcut bazı planlama motorunun üzerine inşa edilmiştir. Aynı mantık laboratuar alt alanına da uygulanabilir: iş vakamızın önemli bir parçası hasta kayıtları ve laboratuvar arasında kusursuz bir entegrasyon ise, o zaman laboratuvar büyük olasılıkla core bir alandır. Aksi takdirde, supporting bir alt alan adıdır.
Sorunlardan Çözümlere
Bazen "problem domain" olarak adlandırılan domaini bulursunuz. Bu, domainin yazılımın çözeceği sorunları tanımlaması gerçeğinden kaynaklanmaktadır (sonuçta, yazılımın ilk etapta yapılmasının bir nedeni vardır). Vaughn Vernon, bir alanı bir problem alanına ve bir çözüm alanına ayırır. Sorun alanı, çözmeye çalıştığımız iş sorunlarına odaklanır. Alt alanlar bu alana aittir.
Çözüm uzayı (solution space), problem uzayındaki (problem space) problemlerin nasıl çözüleceğine odaklanır. Çözüm uzayı daha somut, daha teknik ve daha fazla ayrıntı içerir. Peki sorunlarımızı çözüme nasıl dönüştüreceğiz?
The Ubiquitous Language (Ortak bir dil).
Bir alan adı için yazılım oluşturabilmek için, alanı tanımlamanın bir yoluna ihtiyacınız vardır. İlişkisel bir veri modeline veya benzer bir şeye sahip olmak yeterli değildir. Sadece şeyleri ve onların ilişkilerini değil, aynı zamanda olaylar, süreçler, iş değişmezleri, şeylerin zaman içinde nasıl değiştiği gibi dinamikleri de tanımlayabilmelisiniz. Domain hakkında hem geliştiricilerinizle hem de domain uzmanlarıyla tartışabilmeniz ve mantık yürütebilmeniz gerekir. İhtiyacınız olan şey, ortak bir dildir.
Ortak dil, hem alan uzmanları hem de geliştiriciler tarafından alanı açıklamak ve tartışmak için sürekli olarak kullanılan bir dildir. Kodun kendisinden ayrı olarak, bu dil, Domaine Dayalı Tasarım (DDD) sürecinin en önemli çıktısıdır. Dilin büyük bir kısmı, alan uzmanları tarafından halihazırda kullanılmakta olan alan terminolojisidir, ancak alan uzmanlarıyla işbirliği içinde yeni kavramlar ve süreçler icat etmeniz de gerekebilir. Bu nedenle, alan uzmanlarının aktif katılımı, Domaine Dayalı Tasarım (DDD)'ın başarılı olması için kesinlikle gereklidir. Müşteri alanınızı öğretmek ve ortak bir dil oluşturmanıza yardımcı olmak için zaman ve çaba harcamakla ilgilenmiyorsa, müşteriyi fikrini değiştirmeye ikna etmeye çalışmalı veya başka bir tasarım yöntemi seçmelisiniz.
Ortak dili çeşitli şekillerde belgeleyebilirsiniz. İyi bir başlangıç noktası, bir terimler sözlüğü oluşturmaktır. İş süreçleri, örn. swimline diyagramları ve akış şemaları. UML, farklı şeyler farklı süreçler boyunca ilerlerken durumun nasıl değiştiğini açıklamak için nesneler ve durum diyagramları arasındaki ilişkiyi tanımlamak için kullanılabilir. Alt alan adları da ortak dilin bir parçasıdır ve hatta farklı alt alanlar için dilin farklı "lehçelerini" tanımlamanız gerekebilir. Ortak dilin bu düzenlemesi alan modelidir ve sonunda çalışma koduna dönüştürülecektir. Başka bir deyişle, alan modeli bir veri modeli veya bir UML sınıf diyagramı ile aynı değildir.
Ortak dilin güzel bir özelliği vardır ve bu size doğru yolda olup olmadığınızı söylemesi. Bir iş kavramını veya sürecini dili kullanarak kolayca açıklayabiliyorsanız, doğru yoldasınız demektir. Öte yandan, kendinizi bir şeyi açıklamakta zorlanırken bulursanız, büyük olasılıkla dilden ve dolayısıyla alan modelinizden bir şeyler kaçırıyorsunuzdur. Bu olduğunda, bir alan uzmanı tutmalı ve eksik parçaları aramalısınız. Hatta mevcut modelinizi tamamen tersine çeviren ve daha önce sahip olduğunuzdan çok daha üstün bir domain modeliyle sonuçlanan bir geliştirmeyle karşılaşabilirsiniz.
Introducing Bounded Contexts(Sınırlı Bağlamlara Giriş)
Kusursuz bir dünyada, yeknesak bir dil ve tek bir alanla ilgili her şeyi açıklayacak bir model olurdu. Ne yazık ki, çok küçük ve basit alanlar dışında durum böyle değil. İş süreçleri birbiri içine geçebilir ve hatta çakışabilir. Aynı kelime farklı anlamlara gelebilir veya farklı kelimeler farklı bağlamlarda aynı anlama gelebilir. Nasıl gördüğünüze bağlı olarak, sorun alanında bir sorunu çözmenin birden fazla yolu olabilir (ve genellikle vardır).
Büyük Birleşik Modeli(Big Unified Model) bulmaya çalışmak yerine, gerçekleri kabul etmeyi seçeriz ve bunun yerine sınırlı bağlamlar(bounded context) denen bir şey sunarız. Sınırlı bağlam, yeknesak dilin belirli bir alt kümesinin veya diyalektinin her zaman tutarlı olduğu alanın ayrı bir parçasıdır. Başka bir deyişle, bölme ve yönetme uyguluyor ve domain modelini açıkça tanımlanmış sınırları olan daha küçük, az çok bağımsız modellere ayırıyoruz. Her sınırlı bağlamın kendi adı vardır ve bu ad yeknesak dilin bir parçasıdır.
Sınırlı bağlamlar ve alt alanlar arasında mutlaka bire bir eşleştirme olması gerekmez. Sınırlı bir bağlam çözüm uzayına ve bir alt domain sorun uzayına ait olduğundan, sınırlı bağlamı birçok olası çözüm arasında alternatif bir çözüm olarak düşünmelisiniz. Dolayısıyla, tek bir alt alan, birden çok sınırlı bağlam içerebilir. Kendinizi tek bir sınırlı bağlamın birden çok alt alanı kapsadığı bir durumda da bulabilirsiniz. Buna karşı bir kural yoktur, ancak bu, alt alanlarınızı veya bağlam sınırlarınızı yeniden düşünmeniz gerekebileceğinin bir göstergesidir.
Kişisel olarak, sınırlı bağlamları ayrı sistemler olarak düşünmeyi seviyorum (örneğin, Java dünyasında ayrı çalıştırılabilir JAR'lar veya konuşlandırılabilir WAR'lar). Bunun mükemmel bir gerçek dünya örneği, her mikroservisin kendi sınırlı bağlamı olarak kabul edilebileceği mikroservislerdir. Ancak bu, tüm sınırlı bağlamlarınızı mikroservisler olarak uygulamanız gerektiği anlamına gelmez. Sınırlı bir bağlam, tek bir monolitik sistem içinde ayrı bir alt sistem de olabilir.
Misal
Önceki örnekteki EMR sistemini ve daha spesifik olarak hasta kayıtlarının temel alanını tekrar gözden geçirelim. Orada ne tür sınırlı bağlamlar bulabiliriz? Şimdi sağlık hizmetleri yazılımı konusunda uzman değilim, bu yüzden sadece birkaçını uyduracağım, ama umarım, temel fikri anlarsınız.
Sistem, hem doktor randevuları hem de fizyoterapi için hizmetleri destekler. Ek olarak, yeni hastalar için mülakat yapılan, fotoğraflarının çekildiği ve bir ilk değerlendirmenin verildiği ayrı bir alıştırma süreci vardır. Bu, core domainde aşağıdaki sınırlı bağlamlara yol açar:

- Hastanın kişisel bilgilerini yönetmek için kişisel bilgiler (Personal Information) (isim, adres, mali bilgiler, tıbbi geçmişi, vb.).
- Sisteme yeni hastaları tanıtmak için ilk katılım (Onboarding).
- Doktorların hastayı muayene ederken ve tedavi ederken kullandıkları Tıbbi Muayeneler (Medical Exams).
- Fizyoterapistlerin hastayı muayene ederken ve tedavi ederken kullandıkları fizyoterapi(Physiotherapy).
Çok basit bir sistemde, muhtemelen her şeyi tek bir bağlama sıkıştırırsınız, ancak bu EMR daha gelişmiştir ve sağlanan her hizmet türü için aerodinamik ve optimize edilmiş özellikler sağlar. Ancak, yine de aynı core alt domainindeyiz.
Bağlamlar Arasındaki İlişkiler
Önemsiz olmayan bir sistemde, çok az (varsa) sınırlı bağlam tamamen bağımsızdır. Çoğu bağlamın diğer bağlamlarla bir tür ilişkisi olacaktır. Bu ilişkilerin belirlenmesi sadece teknik olarak (sistemler teknik olarak nasıl iletişim kuracaklar) değil, aynı zamanda nasıl geliştirildikleri (sistemleri geliştiren ekipler birbirleriyle nasıl iletişim kuracaklar) açısından da önemlidir.
Sınırlı bağlamlar arasındaki ilişkileri belirlemenin en basit yolu, bağlamları yukarı akış bağlamları (upstream contexts) ve aşağı akış bağlamları(downstream contexts) olarak sınıflandırmaktır. Bağlamları bir nehrin yanındaki şehirler olarak düşünün. Akış yukarısındaki şehirlerden akan malzemeler aşağıdaki şehirlere ulaşan nehre bir şeyler döküyor. Malzemelerin bir kısmı aşağı havza şehirleri için çok önemlidir ve bu nedenle nehirden geri alırlar. Diğer şeyler zararlıdır ve aşağı havzadaki şehirlere doğrudan zarar verebilir ("pislik yokuş aşağı yuvarlanır").
Yukarı veya aşağı havza olmanın avantajları ve dezavantajları vardır. Bir yukarı akış bağlamı, herhangi bir yönde gelişmesini bir şekilde özgür kılan başka herhangi bir bağlama bağlı değildir. Bununla birlikte, herhangi bir değişikliğin sonuçları aşağı havza bağlamlarında şiddetli olabilir ve bu da, yukarı akış bağlamında kısıtlamalar getirebilir. Aşağı akış bağlamı, yukarı akış bağlamına bağımlılığıyla sınırlıdır, ancak aşağı akış bağlamının geliştiricilerine bir şekilde yukarı akış bağlamının geliştiricilerine göre daha özgür eller veren diğer bağlamları daha aşağı yönde kırma konusunda endişelenmesine gerek yoktur.
Okların aşağı akış bağlamlarından yukarı akış bağlamlarına işaret ettiği bir bağımlılık diyagramı kullanarak veya U ve D rollerini kullanarak ilişkileri grafiksel olarak tanımlayabilirsiniz.

Son olarak, nerede durduğunuza bağlı olarak bir bağlamın aynı anda hem yukarı akış bağlamı hem de aşağı akış bağlamı olabileceğini unutmayın.
Context Maps and Integration Patterns(Bağlam Haritaları ve Entegrasyon Modelleri)
Bağlamlarımızın ne olduğunu ve nasıl ilişkili olduklarını öğrendikten sonra, bunları nasıl bütünleştireceğimize karar vermeliyiz. Bu birkaç önemli soruyu içerir:
- Bağlam sınırları nerede?
- Bağlamlar teknik olarak nasıl iletişim kuracak?
- Bağlamların domain modelleri arasında nasıl harita oluşturacağız (yani yeknesak bir dilden diğerine nasıl çeviri yapıyoruz)?
- Yukarı yönde meydana gelen istenmeyen veya sorunlu değişikliklere karşı nasıl korunacağız?
- Aşağı akış bağlamlarında sorun yaratmaktan nasıl kaçınacağız?
Bu soruların cevapları bir bağlam haritası (context map) halinde derlenecektir. Bağlam haritası şu şekilde grafiksel olarak belgelenebilir:

Bağlam eşlemesini oluşturmayı kolaylaştırmak için, çoğu kullanım durumu için çalışan bir dizi hazır tümleştirme modeli(integration patterns) vardır. Hangi entegrasyon modelini seçtiğinize bağlı olarak, onu gerçekten kullanışlı hale getirmek için bağlam haritasına ek bilgiler eklemeniz gerekebilir.
Partnership(Ortaklık)
Her iki bağlamdaki ekipler işbirliği yapar. Arayüzler - ne olursa olsunlar - her iki bağlamın geliştirme ihtiyaçlarını karşılayacak şekilde gelişir. Birbirine bağlı özellikler, her iki takıma da mümkün olduğunca az zarar verecek şekilde uygun şekilde planlanır ve programlanır.
Shared Kernel (Paylaşılan Çekirdek)
Her iki bağlam da çekirdek olan ortak bir kod tabanını paylaşır. Çekirdek, herhangi bir ekip tarafından değiştirilebilir, ancak önce diğer ekibe danışılmadan yapılamaz. İstenmeyen yan etkilerin ortaya çıkmadığından emin olmak için, sürekli entegrasyon (otomatik test ile) gereklidir. İşleri olabildiğince basit tutmak için, paylaşılan çekirdek mümkün olduğu kadar küçük tutulmalıdır. Paylaşılan çekirdekte çok sayıda model kodu varsa, bu bağlamların aslında tek bir büyük bağlamda birleştirilmesi gerektiğinin bir işareti olabilir.
Customer-Supplier (Müşteri - Satıcı)
Bağlamlar, yukarı akış-aşağı akış ilişkisi içindedir ve bu ilişki, yukarı akış ekibi tedarikçi ve aşağı akış ekibi müşteri olacak şekilde biçimlendirilir. Bu nedenle, her iki takım da kendi sistemleri üzerinde az çok bağımsız olarak çalışabilse de, yukarı akış ekibinin (tedarikçi) aşağı akış ekibinin (müşteri) ihtiyaçlarını hesaba katması gerekir.
Conformist (Uyumlu Kimse)
Bağlamlar yukarı akış-aşağı akış ilişkisi içindedir. Bununla birlikte, yukarı akış ekibinin, aşağı akış ekibinin ihtiyaçlarını karşılamak için hiçbir motivasyonu yoktur (örneğin, daha büyük bir tedarikçiden bir hizmet olarak sipariş edilebilir). Alt ekip, her ne olursa olsun, üst ekip modeline uymaya karar verir.
Anticorruption Layer (Adaptosyon Katmanı)
Bağlamlar yukarı akış-aşağı akış ilişkisi içindedir ve yukarı akış ekibi, aşağı akış ekibinin ihtiyaçlarını umursamaz. Ancak, yukarı akış modeline uymak yerine, aşağı akış ekibi, aşağı akış bağlamını yukarı akış bağlamındaki değişikliklerden koruyan bir soyutlama katmanı oluşturmaya karar verir. Bu adaptasyon katmanı, aşağı akış ekibinin ihtiyaçlarına en çok uyan bir domain modeliyle çalışmasına olanak tanır ve yine de yukarı akış bağlamıyla bütünleşir. Yukarı akış bağlamı değiştiğinde, adaptasyon katmanının da değişmesi gerekir, ancak aşağı akış bağlamının geri kalanı değişmeden kalabilir. Bu stratejiyi, yukarı akış arayüzündeki değişiklikleri tespit etmek için otomatik testlerin kullanıldığı sürekli entegrasyonla birleştirmek iyi bir fikir olabilir.
Open Host Service
Bir sisteme erişim, açıkça tanımlanmış bir protokol kullanılarak, açıkça tanımlanmış hizmetler tarafından sağlanır. Protokol, ihtiyaç duyan herkesin sisteme entegre olabilmesi için açıktır. Web hizmetleri ve mikroservisler, bu entegrasyon modelinin güzel bir örneğidir. Bu örüntü, bağlamlar ve onları geliştiren takımlar arasındaki ilişkiyi önemsemediği için diğerlerinden farklıdır. open host service modelini diğer modellerden herhangi biriyle birleştirebilirsiniz.
Bu kalıbı kullanırken dikkat edilmesi gereken nokta, protokolü basit ve kararlı tutmaktır. Sistem istemcilerinin çoğu bu protokolden ihtiyaç duyduklarını alabilmelidir. Kalan özel durumlar için özel entegrasyon noktaları oluşturun.
Published Language (Yayın Dili)
Bu, şahsen açıklamakta en zorlandığım entegrasyon modeli. Benim baktığım şekilde, yayınlanan dil, open host servisine en yakın olanıdır ve genellikle bu entegrasyon modeliyle birlikte kullanılır. Sistemin girişi ve çıkışı için belgelenmiş bir dil (örneğin XML tabanlı) kullanılır. Yayınlanan dile uyduğunuz sürece belirli bir kitaplığı veya bir şartnamenin belirli bir uygulamasını kullanmaya gerek yoktur. Yayınlanmış dillerin gerçek dünya örnekleri, matematiksel formülleri temsil eden MathML ve coğrafi bilgi sistemlerinde coğrafi özellikleri temsil eden GML'dir.
Lütfen web hizmetlerini yayınlanan bir dille birlikte kullanmanız gerekmediğini unutmayın. Ayrıca bir dosyanın bir dizine bırakıldığı ve çıktıyı başka bir dosyada depolayan bir toplu iş tarafından işlendiği bir kuruluma sahip olabilirsiniz.
Separate Ways (Ayrı Roller)
Bu entegrasyon modeli, herhangi bir entegrasyon gerçekleştirmemesi açısından özeldir. Yine de, alet çantasında tutulması gereken önemli bir kalıptır ve çok fazla para ve zaman tasarrufu sağlayabilir. İki bağlam arasındaki entegrasyonun yararı artık çabaya değmediğinde, bağlamları birbirinden ayırmak ve bağımsız olarak evrimleşmelerine izin vermek daha iyidir. Bunun nedeni, sistemlerin artık birbirleriyle ilişkili olmadıkları bir noktaya evrilmiş olmaları olabilir. Aşağı akış bağlamının fiilen kullandığı yukarı akış bağlamı tarafından sağlanan (birkaç) hizmet, aşağı akış bağlamında yeniden uygulanır.
Stratejik Domaine Dayalı Tasarım Neden Önemlidir?
Stratejik domaine dayalı tasarımın aslında daha büyük projeler için tasarlandığına inanıyorum, ancak projede DDD'nin başka herhangi bir parçasını kullanmasanız bile, bundan daha küçük projelerde de yararlanabileceğinizi düşünüyorum.
Şahsen benim için stratejik domaine dayalı tasarımın başlıca çıkarımları şunlardır:
- Sınırlar getirir. Kapsam sünmesi (Scope creep), tüm hobi projelerimde değişmeyen bir faktördür. Sonunda, üzerinde çalışmak eğlenceden daha kapsamlı hale gelir veya tek başına bitirmek tamamen gerçekçi olmaz. Müşteri projeleri üzerinde çalışırken, bir şeyleri aşırı düşünerek veya aşırı mühendislik yaparak teknik kapsamın sünmesine neden olmamak için çok çalışmam gerekir. Sınırlar - nerede olurlarsa olsunlar - projeyi daha küçük parçalara bölmeme ve doğru zamanda doğru olanlara odaklanmama yardımcı oluyor.
- Her durumda çalışan bir süper model bulmamı gerektirmiyor. Stratejik DDD gerçek dünyada, genellikle az çok açıkça tanımlanmış bağlamlarda birçok küçük modelin olduğunu kabul eder. Bu modelleri kırmak yerine kucaklar.
- Sisteminizin getireceği değeri ve en büyük değeri elde etmek için çabalarınızın çoğunu nereye koymanız gerektiğini düşünmenize yardımcı olur. Doğru bir şekilde tanımlamanın ve ardından core domaine odaklanmanın büyük bir fark yaratacağı projelerden kişisel deneyime sahibim. Ne yazık ki, stratejik DDD'yi henüz duymamıştım ve hem zaman hem de para israf ettim.
Ayrıca, bu yaklaşımla riskleri tanımlayacak kadar iyi olduğumu da biliyorum: alt alanlar ve sınırlı bağlamlar bulmak adına alt alanlar ve sınırlı bağlamlar bulmak. Sevdiğim yeni bir şey öğrendiğimde, onu gerçek dünyada denemeyi çok isterim. Bu bazen orada olmayan şeyleri aramaya gittiğim anlamına gelebilir. Buradaki önerim, her zaman bir core domain ve bir sınırlı bağlam (bounded context) ile başlamaktır. Domain modellemesini dikkatlice yapıyorum, ek alt domainleri ve sınırlı bağlamlar varsa, sonunda kendilerini ortaya cıkaracaklardır.
Çeviri için izin veren Petter Holmström'e teşekkürler.


Bonus :
Barış Velioğlu
Domain Driven Design Kimdir?
2020
Rapor
Teknoloji

Softtech 2020 Teknoloji Raporu
Softtech 2020 Teknoloji Raporu, 2020 yılında teknolojik yenilikleri detaylı halde raporlayan güzel bir çalışma olmuş.
Bahsedilen rapora buradan ulaşabilirsiniz.

NoSQL - İlişkisel Veritabanları (RDMS) Karşılaştırması - mongodb.com çevirisi
Merhaba bu yazımda size mongodb.com'da yayınlanan NoSQL vs Relational Databases başlıklı makaleyi çevireceğim.
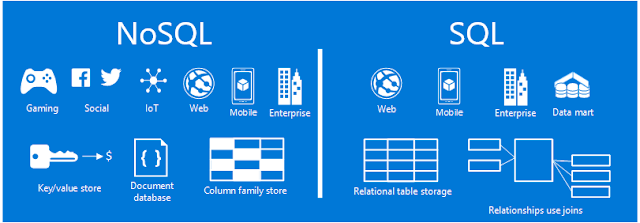
MongoDB gibi bazı NoSQL veritabanları veri yapılarını popüler programlama dillerinin veri haritalarıyla eşler. Bu eşleme, geliştiricilerin verilerini uygulama kodlarında kullandıkları gibi depolamasına olanak tanır. Bu önemsiz bir avantaj gibi görünse de, bu eşleme geliştiricilerin daha az kod yazmalarına olanak tanıyarak daha hızlı geliştirme süresi ve daha az hataya yol açabilir.
NoSQL - İlişkisel Veritabanları (RDMS) Karşılaştırması

Aralarından seçim yapabileceğiniz iki ana modern veritabanı türü ilişkisel ve ilişkisel olmayan , SQL veya NoSQL (sorgu dilleri için) olarak da bilinen veritabanlarıdır. Hangi veritabanının ihtiyaçlarınıza en uygun olduğuna karar verirken aşina olmanız gereken birkaç temel farklılık vardır.
TLDR: NoSQL (“SQL olmayan” veya “sadece SQL” değil) veritabanları, ölçeklendirme, hızlı sorgular, sık uygulama değişikliklerine izin verilmesi ve programcıları geliştiriciler için basitleştirmeye odaklanarak 2000'li yılların sonlarında geliştirilmiştir. SQL (Yapılandırılmış Sorgu Dili) ile erişilen ilişkisel veritabanları, depolama alanı geliştirici süresinden çok daha maliyetli olduğundan veri tekrarını azaltmaya odaklanarak 1970'lerde geliştirilmiştir. SQL veritabanları katı, karmaşık, tablo şeklinde şemalara sahip olma eğilimindedir ve tipik olarak pahalı dikey ölçeklendirme gerektirir.
tldr özeti: SQL veritabanları ilişkisel veritabanları olarak bilinir ve kesin, önceden tanımlanmış bir şema gerektiren tablo tabanlı bir veri yapısına sahiptir. NoSQL veritabanları veya ilişkisel olmayan veritabanları belge tabanlı, grafik veritabanları, anahtar / değer çiftleri veya geniş sütun depoları olabilir. NoSQL veritabanları, önceden yapılandırılmamış bir şema gerektirmez ve "yapılandırılmamış veriler" ile daha serbest çalışmanıza olanak tanır. İlişkisel veritabanları dikey olarak ölçeklendirilebilir, ancak genellikle daha pahalıdır, oysa NoSQL veritabanlarının yatay ölçekleme özelliği daha düşük maliyetlidir.
İlişkisel Veritabanlarının (RDBMS) ve NoSQL'in Tarihçesi
İlişkisel veritabanları (RDBMS) 40 yılı aşkın bir süredir kullanılmaktadır. Tarihsel olarak, veri yapılarının çok daha basit ve statik olduğu zamanlarda iyi çalıştılar. Bununla birlikte, teknoloji ve büyük veri uygulamaları ilerledikçe, geleneksel SQL tabanlı ilişkisel veritabanı hızla genişleyen veri hacimlerini ve veri yapılarının artan karmaşıklıklarını ele almak için daha az donanımlıydı. Son on yılda, ilişkisel olmayan, NoSQL veritabanları geleneksel SQL tabanlı ilişkisel veritabanlarına daha esnek, ölçeklenebilir, düşük maliyetli bir alternatif sunmak için daha popüler hale geldi.
1-Veri Modelleri ve Şema
NoSQL veritabanları dinamik şema içerir ve “yapılandırılmamış veriler” olarak bilinenleri kullanmanızı sağlar. Bu, ilk önce şemayı tanımlamak zorunda kalmadan uygulamanızı oluşturabileceğiniz anlamına gelir. İlişkisel bir veritabanında, veritabanına veri eklemeden önce şemanızı tanımlamanız gerekir. Önceden tanımlanmış bir şemaya ihtiyaç duyulmaması, veri ve gereksinimler değiştikçe NoSQL veritabanlarının güncellenmesini çok daha kolay hale getirir. İlişkisel bir veritabanında şema yapısının değiştirilmesi son derece pahalı, zaman alıcı olabilir ve genellikle kesinti veya hizmet kesintilerini içerebilir.
2-Veri yapısı
İlişkisel veritabanları tablo tabanlıdır. NoSQL veritabanları belge tabanlı, grafik veritabanları, anahtar / değer çiftleri veya geniş sütun depoları olabilir. İlişkisel veritabanları, verilerin çoğunlukla yapılandırıldığı ve ilişkileri tarafından açıkça tanımlandığı bir dönemde oluşturulmuştur. Bugün, bugünkü verilerin çok daha karmaşık olduğunu biliyoruz. NoSQL veritabanları, günümüzde var olan verilerin çoğunu oluşturan daha karmaşık, yapılandırılmamış verileri (metinler, sosyal medya gönderileri, fotoğraflar, videolar, e-posta gibi) işleyecek şekilde tasarlanmıştır.
3-Ölçekleme
İlişkisel veritabanları dikey olarak ölçeklenebilir ancak genellikle pahalıdır. Tüm veritabanını barındırmak için tek bir sunucuya ihtiyaç duyduklarından, ölçeklendirmek için daha büyük ve daha pahalı bir sunucu satın almanız gerekir. NoSQL veritabanını ölçeklendirmek, ilişkisel veritabanına göre çok daha ucuzdur, çünkü ucuz, ticari sunucular üzerinde yatay olarak ölçekleyerek kapasite ekleyebilirsiniz.
4-Geliştirme Modeli
NoSQL veritabanları daha çok açık kaynak topluluğunun bir parçası olma eğilimindedir. İlişkisel veritabanları, yazılımlarının kullanımı için kullanılan lisanslama ücretleri ile tipik olarak kapalı bir kaynaktır.Genel NoSQL ve İlişkisel Veritabanı (diğer adıyla SQL) Soruları
NoSQL SQL'den daha mı iyi?
-NoSQL, daha karmaşık, sürekli değişen veri setlerine sahip ve hemen tanımlanması gerekmeyen esnek bir veri modeli gerektiren modern uygulamalar için daha iyi bir seçenek olma eğilimindedir. NoSQL veritabanlarını tercih eden çoğu geliştirici veya kuruluş, pazara daha hızlı gitmelerini, güncellemeleri daha hızlı hale getirmelerini sağlayan çevik özelliklere ilgi duyuyor. Geleneksel, SQL tabanlı, ilişkisel veritabanlarının aksine, NoSQL veritabanları verileri gerçek zamanlı olarak depolayabilir ve işleyebilir.
-SQL veritabanlarının hala bazı özel kullanım durumları olmasına rağmen, NoSQL veritabanlarının SQL veritabanlarının muazzam maliyetler ve hız, çeviklik vb. Kritik fedakarlıkları olmadan işleyemediği birçok özelliği vardır.
SQL ve NoSQL arasındaki farklar
1-Veri Depolama Modeli :
SQL Veritabanları : Sabit satır ve sütun içeren tablolar
NoSQL Veritabanları : Document: JSON belgeleri, Anahtar / değer: anahtar / değer çiftleri, Geniş sütun: satır ve dinamik sütun içeren tablolar, Grafik: nodes ve edges.
2-Gelişim Tarihi :
SQL Veritabanları : 1970'lerde veri tekrarını azaltmaya odaklanarak geliştirildi
NoSQL Veritabanları : 2000'li yılların sonlarında, çevik ve DevOps uygulamaları tarafından ölçeklendirmeye ve hızlı uygulama değişikliğine izin vererek geliştirildi.
3-Örnekler:
SQL Veritabanları : Oracle, MySQL, Microsoft SQL Server ve PostgreSQL
NoSQL Veritabanları : Belge: MongoDB ve CouchDB, Anahtar / değer çifti: Redis ve DynamoDB, Geniş sütun: Cassandra ve HBase, Grafik: Neo4j ve Amazon Neptün
4-Birincil Amaç:
SQL Veritabanları : Genel amaç
NoSQL Veritabanları : Document(Belge): genel amaçlı, Key/Value(Anahtar / değer): basit arama sorgularıyla büyük miktarlarda veri, Wide-column(Geniş sütun): tahmin edilebilir sorgu desenleriyle büyük miktarlarda veri, Graph(Grafik): bağlı veriler arasındaki ilişkileri analiz etme ve çaprazlama
5-Şemalar :
SQL Veritabanları : Katı
NoSQL Veritabanları : Esnek
6-Ölçekleme :
SQL Veritabanları : Dikey (daha büyük bir sunucu ile ölçeklendirme)
NoSQL Veritabanları : Yatay (emtia sunucularında genişleme)
7-Çok Kayıtlı ACID İşlemleri :
SQL Veritabanları : Destekler
NoSQL Veritabanları : Çoğu çoklu kayıt ACID işlemlerini desteklemez. Ancak, bazıları - MongoDB gibi - destekler.
8-Joins :
SQL Veritabanları : Genellikle gerekli
NoSQL Veritabanları : Genellikle gerekli değildir
9- Verileri Nesne ile Eşleme :
SQL Veritabanları : ORM (nesne-ilişkisel eşleme) gerektirir
NoSQL Veritabanları : Birçoğu ORM gerektirmez. MongoDB belgeleri, en popüler programlama dillerindeki veri yapılarıyla doğrudan eşleşir.
NoSQL Veritabanlarının Faydaları Nelerdir?
NoSQL veritabanları ilişkisel veritabanlarına göre birçok fayda sağlar. NoSQL veritabanlarının esnek veri modelleri vardır, yatay olarak ölçeklendirilir, inanılmaz derecede hızlı sorguları vardır ve geliştiricilerin birlikte çalışması kolaydır.
-Esnek veri modelleri
NoSQL veritabanları genellikle çok esnek şemalara sahiptir. Esnek bir şema, gereksinimler değiştikçe veritabanınızda kolayca değişiklik yapmanızı sağlar. Kullanıcılarınıza daha hızlı değer katmak için yeni uygulama özelliklerini hızlı bir şekilde ve sürekli olarak entegre edebilirsiniz.
-Yatay ölçeklendirme
Çoğu SQL veritabanı, geçerli sunucunuzun kapasite gereksinimlerini aştığınızda dikey olarak ölçeklendirmenizi (daha büyük, daha pahalı bir sunucuya geçmenizi) gerektirir. Tersine, çoğu NoSQL veritabanı yatay olarak ölçeklendirmenize izin verir, yani ihtiyacınız olduğunda daha ucuz, emtia sunucuları ekleyebilirsiniz.
-Hızlı sorgular
NoSQL veritabanlarındaki sorgular SQL veritabanlarından daha hızlı olabilir. Neden? SQL veritabanlarındaki veriler genellikle normalleştirilir, bu nedenle tek bir nesne veya varlık için sorgular birden çok tablodaki verilere katılmanızı gerektirir. Tablolarınız büyüdükçe birleşimler pahalı hale gelebilir. Ancak, NoSQL veritabanlarındaki veriler genellikle sorgular için optimize edilmiş bir şekilde saklanır. MongoDB'yi kullandığınızda temel kural Veri'dir, birlikte erişildiğinde birlikte depolanmalıdır. Sorgular genellikle join gerektirmez, bu nedenle sorgular çok hızlıdır.
-Easy for developers
NoSQL Veritabanlarının Dezavantajları Nelerdir?
NoSQL veritabanlarının en sık belirtilen dezavantajlarından biri, birden fazla belge üzerinde ACID (atomisite, tutarlılık, izolasyon, dayanıklılık) işlemlerini desteklememesidir. Uygun şema tasarımı ile, birçok uygulama için tek kayıt atomisitesi kabul edilebilir.
Bununla birlikte, birden fazla kayıtta ACID gerektiren hala birçok uygulama vardır.Bu kullanım durumlarını ele almak için MongoDB, 4.0 sürümünde çok belgeli ACID işlemleri için destek ekledi ve bunları parçalanmış kümeleri kapsayacak şekilde 4.2'de genişletti.
NoSQL veritabanlarındaki veri modelleri veri tekrarnını azaltmak için değil, genellikle sorgular için optimize edildiğinden, NoSQL veritabanları SQL veritabanlarından daha büyük olabilir. Depolama şu anda o kadar ucuz ki çoğu bunu küçük bir dezavantaj olarak görülür ve bazı NoSQL veritabanları da depolama ayak izini azaltmak için sıkıştırmayı destekliyor.
Seçtiğiniz NoSQL veritabanı türüne bağlı olarak, tüm kullanım durumlarınızı tek bir veritabanında gerçekleştiremeyebilirsiniz. Örneğin, grafik veritabanları verilerinizdeki ilişkileri analiz etmek için mükemmeldir, ancak aralık sorguları gibi verilerin günlük olarak alınması için ihtiyacınız olanları sağlamayabilir. Bir NoSQL veritabanı seçerken, kullanım durumlarınızın ne olacağını ve MongoDB gibi genel amaçlı bir veritabanının daha iyi bir seçenek olup olmadığını düşünün.
microservices
monolotich
Software Architecture
Software Engineering
Monolithic mimarinin nispeten küçük uygulamalarda avantajları ve uygulama büyüdükçe yaşattığı zorluklar
Günümüzde microservice mimariye doğru hızlı bir geçiş var. Microservice mimarinin getiridiği avantajlar yatsınamaz. Fakat Chris Richardson "Microservices Patterns" kitabında küçük uygulamalarda monolotich mimarinin avantajları olduğunu söylüyor.

Bunlar:
1-) Kolay geliştirme : IDE'ler ve diğer geliştirici araçları sadece bir uygulamayı geliştirmek için focus oluyorlar.
2-) Uygulama üzerinde radikal değişiklikler yapabilmek : Radikal bir şekilde kodu, database şemasını kolayca değiştirip build ve deploy yapmanız microservice'e göre çok daha kolay.
3-)Test edilmesi kolay : Geliştiriciler, uygulamayı başlatan, REST API'sini çağıran ve Selenium ile kullanıcı arayüzünü test eden uçtan uca testleri rahatlıkla yazabilirler.
4-) Dağıtımı kolay : Bir geliştiricinin tek yapması gereken, WAR dosyasını Tomcat'in yüklü olduğu bir sunucuya kopyalamaktır.
5-) Ölçeklendirmesi kolay : Uygulamanın birden fazla örneğini bir yük dengeleyicinin arkasında çalıştırabilirsiniz.
Ancak zamanla geliştirme, test, dağıtım ve ölçeklendirme çok daha zor hale gelir. Eğer uygulamanın karmaşıklığı önceden ileride artacağı tahmin edilebiliyorsa microservice mimari ile başlanmadılır. Küçük ve karmaşık olmayan uygulamalar monolotich mimariye daha uygundur.
Monolotich mimari ile yazılan bir uygulama düşünelim. Herbir sprint'de uygulamaya yeni özellikler eklenir ve uygulama code base'i giderek büyür. Buna bağlı olarak yazılım ekibi de giderek kalabalıklaşır. Uygulamayı yönetmek giderek zorlaşmaya başlar. Fonksiyonel olarak ayrılmış Agile takımlar ortaya çıkar. Agile yöntemler kullanmak giderek zor hale gelir.
Uyguluma giderek karmaşıklaştıkca ve büyüdükçe monolotich mimaride yaşanan zorluklar :
1-) Karmaşıklık geliştiricileri korkutur hale gelir : Uygulama çok karmaşık hale geldiğinden hataları düzeltmek ve yeni özellikleri doğru şekilde uygulamak zor ve zaman alıcı hale gelir. Son teslim tarihleri genellikle kaçırılır.
2-) Geliştirme yavaşlar : Büyük uygulama, geliştiricinin IDE'sini aşırı yükler ve yavaşlatır. Uygulamayı build etmek uzun zaman alır. Dahası, çok büyük olduğu için, uygulamanın başlatılması uzun zaman alır. Sonuç olarak, edit-build-run-test döngüsü uzun zaman alır ve bu da üretkenliği kötü etkiler.
3-) Commit'den deployment'a giden uzun ve yorucu yol : Uygulamayla ilgili bir diğer sorun da değişikliklerin üretime aktarılmasının uzun ve acı verici bir süreç olmasıdır. Ekip genellikle ayda bir kez, genellikle Cuma veya Cumartesi gecesi geç saatlerde üretim güncellemelerini dağıtır. Ve continuous deployment benimsemek imkansız gibi görünür. Feature branch'lerinin merge işlemi saatler alabilir ve production'a geçmenin bu kadar uzun sürmesinin bir başka nedeni de testin uzun sürmesidir. Kod tabanı çok karmaşık olduğundan ve bir değişikliğin etkisi iyi anlaşılmadığından, geliştiriciler ve Sürekli Entegrasyon (CI) sunucusu tüm test paketini çalıştırmalıdır.
4-) Ölçeklendirme zor : Bunun nedeni, farklı uygulama modüllerinin çakışan kaynak gereksinimleri olmasıdır. Örneğin uygulamada bazı modüller , çok fazla belleğe sahip sunucularda ideal olarak deploy edilen büyük bellek veritabanında saklanırken, görüntü işleme modülü CPU yoğun bir işlemdir ve en iyi CPU'lara sahip sunucularda en iyi şekilde çalışır. Bu modüller aynı uygulamanın bir parçası olduğundan, sunucu yapılandırmasında bu aşamada ödünler verilmesi gerekir.
5-) Reliable bir monolitich sunmak zor : Reliable olmamasının bir nedeni, büyük boyutu nedeniyle uygulamayı kapsamlı bir şekilde test etmenin zor olmasıdır. Bu test edilebilirlik eksikliği, hataların productiona geçmesi anlamına gelir. Daha da kötüsü, tüm modüller aynı işlem içinde çalıştığından uygulamada hata izolasyonu yoktur. Çoğu zaman, bir modüldeki bir hata - örneğin bir bellek sızıntısı - uygulamanın tüm modullerini tek tek çökertir.
6-) Giderek kullanılmayan teknolojiye mahkum kalmak : Mimarinin giderek modası geçmiş bir teknoloji yığını kullanmaya zorlamasıdır. Monolitik mimari, yeni frameworklerin ve dillerin benimsenmesini zorlaştırmaktadır. Tüm monolitik uygulamayı yeniden yazmak son derece pahalı ve riskli olacaktır, böylece yeni ve muhtemelen daha iyi bir teknoloji kullanamayacaktır. Sonuç olarak, geliştiriciler projenin başlangıcında yaptıkları teknoloji seçimlerine bağlı kalırlar.

Bunlar:
1-) Kolay geliştirme : IDE'ler ve diğer geliştirici araçları sadece bir uygulamayı geliştirmek için focus oluyorlar.
2-) Uygulama üzerinde radikal değişiklikler yapabilmek : Radikal bir şekilde kodu, database şemasını kolayca değiştirip build ve deploy yapmanız microservice'e göre çok daha kolay.
3-)Test edilmesi kolay : Geliştiriciler, uygulamayı başlatan, REST API'sini çağıran ve Selenium ile kullanıcı arayüzünü test eden uçtan uca testleri rahatlıkla yazabilirler.
4-) Dağıtımı kolay : Bir geliştiricinin tek yapması gereken, WAR dosyasını Tomcat'in yüklü olduğu bir sunucuya kopyalamaktır.
5-) Ölçeklendirmesi kolay : Uygulamanın birden fazla örneğini bir yük dengeleyicinin arkasında çalıştırabilirsiniz.
Ancak zamanla geliştirme, test, dağıtım ve ölçeklendirme çok daha zor hale gelir. Eğer uygulamanın karmaşıklığı önceden ileride artacağı tahmin edilebiliyorsa microservice mimari ile başlanmadılır. Küçük ve karmaşık olmayan uygulamalar monolotich mimariye daha uygundur.
Monolotich mimari ile yazılan bir uygulama düşünelim. Herbir sprint'de uygulamaya yeni özellikler eklenir ve uygulama code base'i giderek büyür. Buna bağlı olarak yazılım ekibi de giderek kalabalıklaşır. Uygulamayı yönetmek giderek zorlaşmaya başlar. Fonksiyonel olarak ayrılmış Agile takımlar ortaya çıkar. Agile yöntemler kullanmak giderek zor hale gelir.
Uyguluma giderek karmaşıklaştıkca ve büyüdükçe monolotich mimaride yaşanan zorluklar :
1-) Karmaşıklık geliştiricileri korkutur hale gelir : Uygulama çok karmaşık hale geldiğinden hataları düzeltmek ve yeni özellikleri doğru şekilde uygulamak zor ve zaman alıcı hale gelir. Son teslim tarihleri genellikle kaçırılır.
2-) Geliştirme yavaşlar : Büyük uygulama, geliştiricinin IDE'sini aşırı yükler ve yavaşlatır. Uygulamayı build etmek uzun zaman alır. Dahası, çok büyük olduğu için, uygulamanın başlatılması uzun zaman alır. Sonuç olarak, edit-build-run-test döngüsü uzun zaman alır ve bu da üretkenliği kötü etkiler.
3-) Commit'den deployment'a giden uzun ve yorucu yol : Uygulamayla ilgili bir diğer sorun da değişikliklerin üretime aktarılmasının uzun ve acı verici bir süreç olmasıdır. Ekip genellikle ayda bir kez, genellikle Cuma veya Cumartesi gecesi geç saatlerde üretim güncellemelerini dağıtır. Ve continuous deployment benimsemek imkansız gibi görünür. Feature branch'lerinin merge işlemi saatler alabilir ve production'a geçmenin bu kadar uzun sürmesinin bir başka nedeni de testin uzun sürmesidir. Kod tabanı çok karmaşık olduğundan ve bir değişikliğin etkisi iyi anlaşılmadığından, geliştiriciler ve Sürekli Entegrasyon (CI) sunucusu tüm test paketini çalıştırmalıdır.
4-) Ölçeklendirme zor : Bunun nedeni, farklı uygulama modüllerinin çakışan kaynak gereksinimleri olmasıdır. Örneğin uygulamada bazı modüller , çok fazla belleğe sahip sunucularda ideal olarak deploy edilen büyük bellek veritabanında saklanırken, görüntü işleme modülü CPU yoğun bir işlemdir ve en iyi CPU'lara sahip sunucularda en iyi şekilde çalışır. Bu modüller aynı uygulamanın bir parçası olduğundan, sunucu yapılandırmasında bu aşamada ödünler verilmesi gerekir.
5-) Reliable bir monolitich sunmak zor : Reliable olmamasının bir nedeni, büyük boyutu nedeniyle uygulamayı kapsamlı bir şekilde test etmenin zor olmasıdır. Bu test edilebilirlik eksikliği, hataların productiona geçmesi anlamına gelir. Daha da kötüsü, tüm modüller aynı işlem içinde çalıştığından uygulamada hata izolasyonu yoktur. Çoğu zaman, bir modüldeki bir hata - örneğin bir bellek sızıntısı - uygulamanın tüm modullerini tek tek çökertir.
6-) Giderek kullanılmayan teknolojiye mahkum kalmak : Mimarinin giderek modası geçmiş bir teknoloji yığını kullanmaya zorlamasıdır. Monolitik mimari, yeni frameworklerin ve dillerin benimsenmesini zorlaştırmaktadır. Tüm monolitik uygulamayı yeniden yazmak son derece pahalı ve riskli olacaktır, böylece yeni ve muhtemelen daha iyi bir teknoloji kullanamayacaktır. Sonuç olarak, geliştiriciler projenin başlangıcında yaptıkları teknoloji seçimlerine bağlı kalırlar.
DDD
Software Architecture
Software Engineering
Tactical DDD
"Bu makale dizisinde, Domain Driven Desgin (etki alnına dayalı tasarım)'ın ne olduğunu ve projenize - veya bir kısmının - projelerinize nasıl uygulanacağını öğreneceksiniz." diyor Petter Holmström. Ben de elimden geldiğince bu yazı dizisini Türkçe'ye çevirmeye çalışacağım. Umarım İngilizce okumada zorluk çeken arkadaşlar için yararlı olur.
Yazı Dizisinin Orjinali
Örnek DDD projesi
Serinin diğer yazıları :
1 - Strategic Domain Driven Design (Stratejik DDD)
3 - Domain-Driven Design and the Hexagonal Architecture (DDD ve Altıgen Mimari)
Yine, içerik büyük ölçüde Eric Evans'ın Domain-Driven Design: Tackling Complexity in the Heart of Software(Yazılımın Kalbinde Karmaşıklıkla Mücadele) ve Vaughn Vernon tarafından yazılan Implementing Domain-Driven Design kitaplarına dayanıyor ve her ikisini de okumanızı şiddetle tavsiye ediyorum. Önceki makalede olduğu gibi, kendi sözlerimle mümkün olduğunca açıklamayı seçtim, uygun olduğunda kendi fikirlerimi, düşüncelerimi ve deneyimlerimi enjekte ettim.
Value Objects
Taktiksel DDD'deki en önemli kavramlardan biri değer nesnesidir. Bu aynı zamanda DDD olmayan projelerde en çok kullandığım DDD yapı taşıdır ve umarım bunu okuduktan sonra siz de kullanırsınız.
Java'da bir StreetAddress değer nesnesi ve karşılık gelen builder şöyle görünebilir (kod test edilmemiştir ve netlik için bazı yöntem uygulamaları atlanmıştır):
StreetAddress.java
Entities
Entity or Value Object?
(Varlık veta Değer Nesnesi)
Bu örnekte dikkat edilmesi gereken bazı noktalar:
Şimdi DDD ve CRUD ile ilgili soruyu yanıtlamanın uygun olduğu bir noktaya geldik. CRUD, Oluşturma(Create), Okuma(retrieve), Güncelleme(Update) ve Silme(Delete) anlamına gelir ve aynı zamanda kurumsal uygulamalarda ortak bir kullanıcı arayüzü modelidir:

Aggregates


Agregalar tasarlarken, takip edilmesi gereken belirli yönergeler vardır. Onları kurallardan ziyade yönergeler olarak adlandırmayı seçiyorum çünkü onları kırmanın mantıklı olduğu durumlar var.
Her durumda, agregalar arasında çift yönlü ilişkilerden kaçınmalısınız.
YÖNERGE 3: TRNASACTION BAŞINA BİR AGREGA DEĞİŞTİRİN
İşlemlerinizi, tek bir transaction içinde yalnızca bir agregada değişiklik yapacak şekilde tasarlamaya çalışın. Birden çok agrega içeren işlemler için domain eventlerini ve nihai tutarlılığı kullanın (bunun hakkında daha fazla konuşacağız). Bu, istenmeyen yan etkileri önler ve gerekirse sistemin gelecekte distribute edilmesini kolaylaştırır. Ayrıca, document veritabanlarının transaction desteği olmadan kullanılmasını da kolaylaştırır.

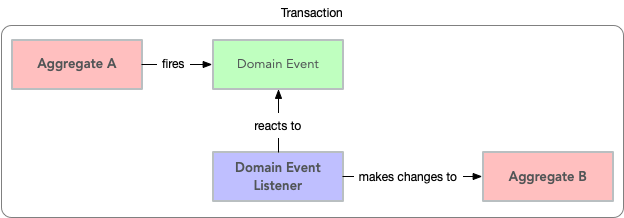
Her durumda, bir agreganın durumunu doğrudan başka bir agreganın içinden değiştirmekten kaçınmalısınız.
Domain eventlerini ele aldığımızda bununla ilgili daha fazla tartışacağız.
YÖNERGE 4: OPTIMISTIC LOCKING KULLANIN
Agregaların temel özelliği, business değişmezlerini zorlamak ve veri tutarlılığını her zaman sağlamaktır. Agrega, çakışan veri depolama güncellemeleri nedeniyle bozulursa, bu durum boşuna olur. Bu nedenle, agregaları kaydederken veri kaybını önlemek için optimistic locking kullanmalısınız.
Optimistic locking'in pestimistic locking'e tercih edilmesinin nedeni, eğer persistence framework optimistic locking'i desteklemiyorsa bunu kendinizin gerçekleştirebilmesi ve distribute edilmesinin ve ölçeklendirmenin kolay olmasıdır.
Küçük agregalar (ve dolayısıyla küçük transactionlar) de çatışma riskini azalttığı için ilk yönergeye bağlı kalmak da bu konuda yardımcı olacaktır.
Agregalar, Değişmezler, Kullanıcı Arayüzü Bağlama ve Doğrulama
Bazılarınız büyük olasılıkla şimdi agregaların ve zorlayıcı iş değişmezlerinin kullanıcı arayüzleriyle birlikte nasıl çalıştıklarını ve daha spesifik olarak bağlayıcı oluşturduklarını merak ediyorsunuz. Değişmezler her zaman uygulanacaksa ve bir agreganın her zaman tutarlı bir durumda olması gerekiyorsa, kullanıcı formları doldururken ne yaparsınız? Ayrıca, setterlar yoksa, form alanlarını agregalara nasıl bağlarsınız?
Bununla baş etmenin birçok yolu vardır. En basit çözüm, agrega kaydedilene kadar değişmez zorlamayı ertelemek, tüm özellikler için setter'lar eklemek ve entityleri doğrudan forma bağlamaktır. Ben şahsen bu yaklaşımı sevmiyorum çünkü bu DDD olmaktan çok veri güdümlü olduğuna inanıyorum. Entitylerin, business logic'i bir hizmet katmanında (veya daha kötüsü, kullanıcı arayüzünde) sonuçlanacak şekilde anemik veri sahiplerine ayrılma riski yüksektir.
bkz : anemic domain model
Bunun yerine, diğer iki yaklaşımı tercih ediyorum. Birincisi, formları ve içeriklerini kendi domain modeli kavramlarına modellemektir. Gerçek dünyada, bir şey için başvurursanız, genellikle bir başvuru formu doldurmanız ve göndermeniz gerekir. Uygulama daha sonra işlenir ve gerekli tüm bilgiler sağlandıktan ve kurallara uyduğunuzda, uygulama çalışır ve başvurduğunuz her şeyi alırsınız. Domain modelinde bu işlemi taklit edebilirsiniz. Örneğin, Üyelik agrega kökü varsa, Üyelik oluşturmak için gereken tüm bilgileri toplamak için kullanılan bir MembershipApplication agrega köküne de sahip olabilirsiniz. Uygulama nesnesi daha sonra üyelik nesnesi oluşturulurken girdi olarak kullanılabilir.
İkinci yaklaşım birincinin bir varyantıdır ve essence pattern'idir. Düzenlemeniz gereken her varlık veya değer nesnesi için aynı bilgileri içeren değiştirilebilir(mutable) bir essence nesne oluşturun. Bu essence nesne daha sonra forma bağlanır. Essence nesnesi gerekli tüm bilgileri içerdikten sonra, gerçek varlıklar veya değer nesneleri oluşturmak için kullanılabilir. İlk yaklaşımın farkı, essence nesnelerin domain modelinin bir parçası olmaması, sadece gerçek domain nesneleriyle etkileşimi kolaylaştırmak için var olan teknik yapılardır. Pratikte, essence pattern böyle bir şeye benzeyebilir:
İsterseniz, bu kalıba daha aşina iseniz essence'i bir builder ile değiştirebilirsiniz. Sonuç aynı olurdu.
KOD ÖRNEKLERİ
Aşağıda, local ID'ye sahip bir agreaga kök (Order) ve bir local varlık (OrderItem) örneği verilmiştir (kod test edilmemiştir ve netlik için bazı metod uygulamaları atlanmıştır):
Order.java
OrderItem.java
Domain Events
(Domain Olayları)
Şimdiye kadar yalnızca domain modelindeki "şeylere" baktık. Bununla birlikte, bunlar sadece modelin herhangi bir anda bulunduğu statik durumu tanımlamak için kullanılabilir. Birçok iş modelinde, gerçekleşen şeyleri tanımlamanız ve modelin durumunu değiştirebilmeniz gerekir. Bunun için domain eventlerini kullanabilirsiniz.
Domain eventleri Evans'ın DDD hakkındaki kitabına dahil edilmedi. Araç kutusuna daha sonra eklendi ve Vernon’un kitabına dahil edildi.
Bir domain eventi, domain modelinde, sistemin diğer bölümlerini ilgilendirebilecek herhangi bir şeydir. Domain eventleri, kaba taneli(coarse-grained) (ör. Belirli bir agrega kök oluşturulur veya bir işlem başlatılır) veya ince taneli(fine-grained) (ör. Belirli bir agrega kökün belirli bir özniteliği değiştirilir) olabilir.
Bir domain eventi yayınlandıktan sonra, bir veya daha fazla domain eventi dinleyicisi tarafından alınabilir ve bu da ek işleme ve yeni domain eventlerini tetikleyebilir. Yayıncı, eventin ne olduğunun farkında değildir ve dinleyici de yayıncıyı etkileyemez (diğer bir deyişle, domain eventlerini yayınlamak yayıncının bakış açısından yan etki içermemelidir). Bu nedenle, domain event dinleyicilerinin eventi yayımlayan ile aynı işlem içinde çalıştırılmaması önerilir.
Tasarım açısından bakıldığında, domain eventlerinin en büyük avantajı sistemi genişletilebilir hale getirmeleridir. Mevcut kodu değiştirmek zorunda kalmadan yeni iş mantığını tetiklemek için ihtiyaç duyduğunuz sayıda domain event dinleyicisi ekleyebilirsiniz. Bu doğal olarak doğru eventlerin ilk etapta yayınlandığını varsayar. Bazı eventlerin önceden farkında olabilirsiniz, ancak diğerleri kendilerini yolda daha fazla gösterecektir. Elbette, ne tür eventlere ihtiyaç duyulacağını tahmin etmeye ve bunları modelinize eklemeye çalışabilirsiniz, ancak daha sonra hiçbir yerde kullanılmayan domain eventleriyle sistemi tıkama riski de vardır. Daha iyi bir yaklaşım, domain eventlerini yayınlamayı mümkün olduğunca kolaylaştırmak ve daha sonra bunlara ihtiyacınız olduğunu fark ettiğinizde eksik eventleri eklemektir.
Event Kaynaklarına İlişkin Not
Event kaynağı, bir sistemin durumunun düzenli bir event günlüğü olarak devam ettiği bir tasarım modelidir. Her biri sistemin durumunu değiştirir ve mevcut durum, event günlüğünü baştan sona tekrar oynatarak herhangi bir zamanda hesaplanabilir. Bu örüntü, özellikle tarihin mevcut durum kadar önemli (hatta daha önemli) olduğu finansal defterler veya tıbbi kayıtlar gibi uygulamalarda kullanışlıdır.
Deneyimlerime göre, tipik bir iş sisteminin çoğu bölümü event kaynağı gerektirmez, ancak bazı bölümleri gerektirir. Tüm sistemi event kaynağı oluşturmayı bir kalıcılık modeli olarak kullanmaya zorlamak, bence, aşırıya kaçmak olacaktır. Ancak, domain eventlerinin gerektiğinde event kaynağı oluşturmak için kullanılabileceğini buldum. Uygulamada, bu, modelin durumunu değiştiren her işlemin, bazı event günlüğünde depolanan bir domain eventi de yayınlayacağı anlamına gelir. Bunun teknik olarak nasıl yapılacağı bu yazının kapsamı dışındadır.
Domain Eventlerini Dağıtma
Domain eventleri yalnızca bunları dinleyicilere dağıtmanın güvenilir bir yoluna sahipseniz kullanılabilir. Bir monolitin içinde, standart observer desenini kullanarak bellek içi dağılımı işleyebilirsiniz. Ancak, bu durumda bile, event yayıncılarını ayrı transactionlarda çalıştırmanın en iyi yöntemlerini izlerseniz daha karmaşık bir şeye ihtiyacınız olabilir. Event dinleyicilerinden biri başarısız olursa ve event yeniden gönderilirmesi gerekirse ne olur?
Vernon, hem uzaktan hem de local olarak çalışan eventleri dağıtmanın iki farklı yolunu sunar. Detaylar için kitabını okumanızı tavsiye ederim ama buradaki seçeneklerin kısa bir özetini vereceğim.
MESAJ KUYRUĞU İLE DAĞITIM
Bu çözüm, AMQP veya JMS gibi harici bir mesajlaşma çözümü (MQ) gerektirir. Çözüm, publish-subscribe modelini ve garantili teslimatı desteklemelidir. Bir domain eventi yayınlandığında, publisher eventi MQ'ya gönderir. Domain event dinleyicileri MQ'ya abone olur ve hemen bilgilendirilir.

Bu modelin avantajları, hızlı, uygulanması oldukça kolay ve mevcut denenmiş ve gerçek mesajlaşma çözümlerine güvenmesidir. Dezavantajları, MQ çözümünü kurmanız ve sürdürmeniz gerektiğidir ve yeni bir tüketici abone olursa geçmiş olayları almanın bir yolu yoktur.
EVENT LOG İLE DAĞILIMI
Bu çözüm ek bileşen gerektirmez, ancak kodlama gerektirir. Bir domain eventi yayınlandığında, log'a eklenir. Domain event dinleyicileri, yeni eventleri kontrol etmek için bu logu düzenli olarak yoklar. Ayrıca, her seferinde tüm logu gözden geçirmek zorunda kalmamak için zaten hangi eventleri işlediklerini takip ederler.

Bu modelin avantajları, herhangi bir ek bileşen gerektirmemesi ve yeni event dinleyicileri için tekrarlanabilen eksiksiz bir olay geçmişi içermesidir. Dezavantajı, uygulanması için biraz çalışma gerektirmesi ve bir dinleyici tarafından yayınlanan ve alınan bir event arasındaki gecikmenin en çok yoklama aralığında olmasıdır.
Nihai Tutarlılık Üzerine Bir Not
Veri tutarlılığı, dağıtılmış sistemlerde veya aynı mantıksal transactionda birden fazla veri deposunun yer aldığı bir sorundur. Gelişmiş uygulama sunucuları, bu sorunu çözmek için kullanılabilen dağıtılmış işlemleri destekler, ancak özel yazılım gerektirirler ve yapılandırılması ve bakımı karmaşık işler olabilir. Güçlü tutarlılık mutlak bir gereklilikse, dağıtılmış transactionları kullanmaktan başka seçeneğiniz yoktur, ancak birçok durumda güçlü tutarlılığın aslında bir iş açısından o kadar da önemli olmadığı ortaya çıkabilir. Biz sadece tek bir ACID transactionunda tek bir veritabanı ile konuşan tek bir uygulamamız olduğu zamanlardan beri güçlü tutarlılık açısından düşünmeye alışkınız.
Güçlü tutarlılığın alternatifi nihai tutarlılıktır. Bu, uygulamadaki verilerin nihayetinde tutarlı hale geleceği anlamına gelir, ancak sistemin tüm bölümlerinin birbiriyle senkronize olmadığı ve mükemmel derecede iyi olduğu zamanlar olacaktır. Nihai tutarlılık için bir uygulama tasarlamak farklı bir düşünme yöntemi gerektirir, ancak bunun karşılığında, yalnızca güçlü tutarlılık gerektiren bir sistemden daha esnek ve ölçeklenebilir bir sistem elde edilebilir.
DDD bir sistemde domain eventleri, nihai tutarlılığa ulaşmanın mükemmel bir yoludur. Başka bir modülde veya sistemde bir şey olduğunda kendini güncellemesi gereken herhangi bir sistem veya modül, o sistemden gelen domain eventlerine abone olabilir:

Aşağıda, sipariş gönderildiğinde bir domain eventi (OrderShipped) yayınlayan bir agrega kök (Order) örneği verilmiştir. Bir domain dinleyicisi (InvoiceCreator) eventi alır ve ayrı bir işlemde yeni bir fatura oluşturur. Agrega kök kaydedildiğinde kayıtlı tüm eventleri yayınlayan bir mekanizma olduğu varsayılmaktadır (kod test edilmemiştir ve netlik için bazı yöntem uygulamaları atlanmıştır):
OrderShipped.java
Order.java
InvoiceCreator.java
Hareketli ve Statik Nesneler
Devam etmeden önce, sizi hareketli ve statik nesnelere tanıtmak istiyorum. Bunlar gerçek DDD terimleri değil, domain modelinin farklı bölümlerini düşündüğümde kendim kullandığım bir şey. Benim dünyamda, taşınabilir bir nesne, birden fazla örneği olabilen ve uygulamanın farklı bölümleri arasında geçirilebilen herhangi bir nesnedir. Değer nesneleri, varlıklar ve domain eventlerinin tümü taşınabilir nesnelerdir.
Öte yandan, statik bir nesne, her zaman tek bir yerde duran ve uygulamanın diğer bölümleri tarafından çağrılan ancak nadiren (diğer statik nesnelere enjekte edilenler hariç) geçirilen singleton (veya pooled bir kaynak) 'tır. Repositoryler, domain servisleri ve factorylerin tümü statik nesnelerdir.
Bu fark önemlidir çünkü nesneler arasında ne tür ilişkileriniz olabileceğini belirler. Statik nesneler, diğer statik nesnelere ve taşınabilir nesnelere referans tutabilir.
Taşınabilir nesneler, diğer hareketli nesnelerin referansını tutabilir. Ancak, hareketli bir nesne hiçbir zaman statik bir nesneye başvuru yapamaz. Taşınabilir bir nesnenin statik bir nesneyle etkileşime girmesi gerekiyorsa, statik nesnenin kendisiyle etkileşime girecek metoda bir metod parametresi olarak iletilmesi gerekir. Bu, taşınabilir nesneleri daha taşınabilir ve bağımsız bir hale getirir, çünkü her seferinde deserialize ettiğimizde statik nesnelere herhangi bir referansa bakmanız ve enjekte etmeniz gerekmez.
Diğer Domain Nesneleri
DDD kodla çalışırken, bir sınıfın değer nesnesine, varlık veya domain event kalıbına gerçekten uymadığı durumlarda karşılaşacağınız zamanlar olacaktır. Deneyimlerime göre, bu genellikle aşağıdaki durumlarda olur:

User.java (identity management)
Çalışan yönetimi bağlamında, yalnızca kullanıcı ID'sne ve adına ihtiyacımız var. Kullanıcı ID ile benzersiz bir şekilde tanımlanır, ancak ad kullanıcı arayüzünde gösterilir. Açıkçası herhangi bir kullanıcı bilgisini değiştiremeyiz, böylece kullanıcı bilgileri değiştirilemez. Kod şöyle görünür:
User.java (employee management)
Repositories
Artık domain modelinin tüm hareketli nesnelerini ele aldık ve artık statik olanlara geçme zamanı. İlk statik nesne repository'dir. Bir repository, agregaların peristence konteynırıdır. Bir repository'e kaydedilen tüm agregalar, sistem yeniden başlatıldıktan sonra bile daha sonra oradan alınabilir.
Bir repository'nin en azından aşağıdaki yetenekleri olmalıdır:
CQRS Hakkında Bir Not
Repository'ler her zaman agregaları kaydeder ve alır. Bu, nasıl uygulandıklarına ve her bir agrega için oluşturulması gereken nesne grafiklerinin boyutuna bağlı olarak oldukça yavaş olabileceği anlamına gelir. Bu, UX açısından sorunlu olabilir ve özellikle iki kullanım durumu akla gelir. Birincisi, yalnızca bir veya iki özellik kullanarak agrega listesini göstermek istediğiniz küçük bir listedir. Yalnızca birkaç öznitelik değerine ihtiyacınız olduğunda eksiksiz bir nesne grafiği oluşturmak zaman kaybı ve bilgi işlem kaynaklarıdır ve genellikle yavaş bir kullanıcı deneyimine yol açar. Başka bir durum, bir listede tek bir öğeyi göstermek için birden fazla agregadaki verileri birleştirmeniz gerektiğidir. Bu, daha kötü performansa neden olabilir.
Veri setleri ve agregalar küçük olduğu sürece, performans kaybı kabul edilebilir, ancak performansın kabul edilebilir olmadığı zaman gelirse bir çözüm vardır: Komut Sorgu Sorumluluk Ayrımı (Command Query Responsibility Segregation)(CQRS).

Domain Services(Domain Servisleri)
Domain modeli, örneğin bir dependency injection framework kullanılarak bağlandığında, bu arabirimin doğru uygulamasını enjekte edebilirsiniz. Local cache çağıran bir servvise, veya uzak bir web servisi çağıran bir servise sahip olabilirsiniz; bir diğeri yalnızca test amacıyla kullanılıabilir vb.
Factories
Modules
2- Tactical Domain-Driven Design (Java Kod Örnekleri İle) - vaadin.com - Petter Holmström - Çevirsi
"Bu makale dizisinde, Domain Driven Desgin (etki alnına dayalı tasarım)'ın ne olduğunu ve projenize - veya bir kısmının - projelerinize nasıl uygulanacağını öğreneceksiniz." diyor Petter Holmström. Ben de elimden geldiğince bu yazı dizisini Türkçe'ye çevirmeye çalışacağım. Umarım İngilizce okumada zorluk çeken arkadaşlar için yararlı olur.
Yazı Dizisinin Orjinali
Örnek DDD projesi
Serinin diğer yazıları :
1 - Strategic Domain Driven Design (Stratejik DDD)
3 - Domain-Driven Design and the Hexagonal Architecture (DDD ve Altıgen Mimari)
2 - Tactical Domain-Driven Design
(Taktiksel DDD)
Bu yazıda taktiksel DDD tasarım hakkında bilgi edineceğiz. Taktiksel DDD, DDD sistemleri tasarlamak için kullanabileceğiniz bir dizi tasarım deseni ve yapı taşıdır. DDD olmayan projeler için bile, bazı taktiksel DDD kalıplarını kullanmaktan faydalanabilirsiniz.
Stratejik DDD tasarıma kıyasla, taktiksel DDD çok daha uygulamalı ve gerçek koda daha yakındır. Stratejik tasarım soyut varlıklarla ilginelirken, taktiksel tasarım sınıflar ve modüller ile ilgilidir. Taktiksel tasarımın amacı, DDD modelini çalışma koduna dönüştürülebilecek bir aşamaya geçirmektir.
Tasarım yinelemeli bir süreçtir ve bu nedenle stratejik ve taktiksel tasarımı birleştirmek mantıklıdır. Stratejik tasarım ile başlayan süreç ardından taktiksel tasarım ile devam eder. En büyük DDD modeli atılımları muhtemelen taktiksel tasarım sırasında gerçekleşecek ve bu da stratejik tasarımı etkileyelerek süreci tekrarlayabilme ihtimali oluşacaktır.
Bu kısa tanıtım ile, taktiksel DDD araç kutusunu ortaya çıkarmanın ve içinde ne olduğuna bir göz atmanın zamanı geldi.
(Değer Nesneleri)
Taktiksel DDD'deki en önemli kavramlardan biri değer nesnesidir. Bu aynı zamanda DDD olmayan projelerde en çok kullandığım DDD yapı taşıdır ve umarım bunu okuduktan sonra siz de kullanırsınız.
Değer nesnesi, değeri önem taşıyan bir nesnedir. Bu, tam olarak aynı değere sahip iki değer nesnesinin aynı değer nesnesi olarak kabul edilebileceği ve dolayısıyla birbirinin yerine geçebileceği anlamına gelir. Bu nedenle, değer nesneleri her zaman değişmez (immutable) kılınmalıdır. Değer nesnesinin durumunu değiştirmek yerine, yeni bir örnekle değiştirirsiniz. Karmaşık değerli nesneler için builder veya essence tasarım kalıplarını kullanmayı düşünün.
Değer nesneleri yalnızca veri kapları değildir, aynı zamanda business mantığı da içerebilir. Değer nesnelerinin aynı zamanda değişmez (immutable) olması, business işlemlerini hem thread-safe hem de yan etkilere kapalı yapar. Bu, değer nesnelerini çok sevmemin nedenlerinden biri ve neden domain kavramlarınızı (domain concepts) değer nesneleri olarak mümkün olduğunca çok modellemeye çalışmanız gerektiğidir. Ayrıca, değer nesnelerini mümkün olduğunca küçük ve tutarlı hale getirmeye çalışın - bu onların bakımını ve yeniden kullanımını kolaylaştırır.
Değer nesneleri yapmak için iyi bir başlangıç noktası, bir business anlamı olan tüm tek değerli özellikleri almak ve bunları değer nesneleri olarak sarmaktır. Örneğin:
- Parasal değerler için bir BigDecimal kullanmak yerine, BigDecimal'ı saran bir Money değeri nesnesi kullanın. Birden fazla para birimi ile uğraşıyorsanız, bir Currency değer nesnesi de oluşturarak, Money nesnenizin bir BigDecimal-Currency çiftini sarmasını isteyebilirsiniz.
- Telefon numaraları ve e-posta adresleri için String kullanmak yerine, Stringleri saran PhoneNumber ve EmailAddress değer nesnelerini kullanın.
Bunun gibi değer nesneleri kullanmanın birçok avantajı vardır. Her şeyden önce, değere bağlam (context) getirir. Belirli bir String'in telefon numarası, e-posta adresi, ad veya posta kodu içerip içermediğini veya BigDecimal'in parasal bir değer, yüzde veya tamamen farklı bir şey olup olmadığını bilmeniz gerekmez. Tipin kendisi hemen neyle uğraştığınızı söyler.
İkinci olarak, belirli bir tipdeki değerler üzerinde gerçekleştirilebilecek tüm business işlemlerini değer nesnesinin kendisine ekleyebilirsiniz. Örneğin, bir Money nesnesi, temeldeki BigDecimal'in hassasiyetinin her zaman doğru olmasını ve işleme dahil olan tüm Money nesnelerinin aynı para birimine sahip olmasını sağlarken, para ekleme ve çıkarma veya yüzde hesaplama işlemleri içerebilir.
Üçüncü olarak, değer nesnesinin her zaman geçerli bir değer içerdiğinden emin olabilirsiniz. Örneğin, EmailAddress değer nesnenizin yapıcısında e-posta adresi String değerini validate edebilirsiniz.
KOD ÖRNEKLERİ
Java'daki bir Money değer nesnesi böyle bir şeye benzeyebilir (kod test edilmemiştir ve netlik için bazı yöntem uygulamaları atlanmıştır):
Money.java
public class Money implements Serializable, Comparable<Money> {
private final BigDecimal amount;
private final Currency currency; // Currency is an enum or another value object
public Money(BigDecimal amount, Currency currency) {
this.currency = Objects.requireNonNull(currency);
this.amount = Objects.requireNonNull(amount).setScale(currency.getScale(), currency.getRoundingMode());
}
public Money add(Money other) {
assertSameCurrency(other);
return new Money(amount.add(other.amount), currency);
}
public Money subtract(Money other) {
assertSameCurrency(other);
return new Money(amount.subtract(other.amount), currency);
}
private void assertSameCurrency(Money other) {
if (!other.currency.equals(this.currency)) {
throw new IllegalArgumentException("Money objects must have the same currency");
}
}
public boolean equals(Object o) {
// Check that the currency and amount are the same
}
public int hashCode() {
// Calculate hash code based on currency and amount
}
public int compareTo(Money other) {
// Compare based on currency and amount
}
}
Java'da bir StreetAddress değer nesnesi ve karşılık gelen builder şöyle görünebilir (kod test edilmemiştir ve netlik için bazı yöntem uygulamaları atlanmıştır):
StreetAddress.java
public class StreetAddress implements Serializable, Comparable<StreetAddress> {
private final String streetAddress;
private final PostalCode postalCode; // PostalCode is another value object
private final String city;
private final Country country; // Country is an enum
public StreetAddress(String streetAddress, PostalCode postalCode, String city, Country country) {
// Verify that required parameters are not null
// Assign the parameter values to their corresponding fields
}
// Getters and possible business logic methods omitted
public boolean equals(Object o) {
// Check that the fields are equal
}
public int hashCode() {
// Calculate hash code based on all fields
}
public int compareTo(StreetAddress other) {
// Compare however you want
}
public static class Builder {
private String streetAddress;
private PostalCode postalCode;
private String city;
private Country country;
public Builder() { // For creating new StreetAddresses
}
public Builder(StreetAddress original) { // For "modifying" existing StreetAddresses
streetAddress = original.streetAddress;
postalCode = original.postalCode;
city = original.city;
country = original.country;
}
public Builder withStreetAddress(String streetAddress) {
this.streetAddress = streetAddress;
return this;
}
// The rest of the 'with...' methods omitted
public StreetAddress build() {
return new StreetAddress(streetAddress, postalCode, city, country);
}
}
}
Entities
(Varlıklar)
Taktiksel DDD'de ikinci önemli kavram ve değer nesnelerine(value objects) kardeş varlık'tır(Entity). Varlık, kimliği önem taşıyan bir nesnedir. Bir varlığın kimliğini belirleyebilmek için, her varlığın, varlık yaratıldığında atanan ve varlığın ömrü boyunca değişmeden kalan benzersiz bir ID'si vardır.
Aynı türden ve aynı ID'ye sahip iki varlık, diğer tüm özellikler farklı olsa bile aynı varlık olarak kabul edilir. Aynı şekilde, aynı tipte ve aynı özelliklere sahip ancak farklı ID'lere sahip iki varlık, tıpkı aynı ada sahip iki kişi aynı kabul edilmez.
Değer nesnelerin aksine, varlıklar değiştirilebilir. Ancak bu, her özellik için setter metodlar oluşturmanız gerektiği anlamına gelmez. Tüm durum değiştirme işlemlerini, business işlemlere karşılık gelen fiiller olarak modellemeye çalışın. Bir setter size yalnızca hangi özelliği değiştirdiğinizi söyler, ancak nedenini söylemez. Örneğin: bir EmploymentContract varlığınız olduğunu ve bunun bir endDate özelliği olduğunu varsayalım. EmployeeContracts'da kontratlar sadece, geçici olmaları, başlangıçta bir şirket şubesinden diğerine iç transfer nedeniyle, çalışan istifa etmesi veya işverenin çalışanı işten çıkarması nedeniyle sona erebilir. Tüm bu durumlarda, endDate değiştirilir, ancak çok farklı nedenlerle. Ayrıca, sözleşmenin neden sona erdiğine bağlı olarak yapılması gereken başka önlemler de olabilir. Bir terminateContract (reason, finalDay) metodu zaten bir setEndDate (finalDay) metodundan çok daha fazlasını söyler.
Bununla birlikte, setter'lerin DDD'de yeri hala var. Yukarıdaki örnekte, bitiş tarihini ayarlamadan önce başlangıç tarihinden sonra olduğundan emin olan özel bir setEndDate (..) metodu olabilir. Bu belirleyici diğer varlık metodları tarafından kullanılır, ancak dış dünyaya açılmaz. Ana ve referans verileri ile bir varlığın business state'ini değiştirmeden tanımlayan özellikler için, setter'leri kullanmak metodları fiillere dönüştürmeye çalışmaktan daha mantıklıdır. SetDescription (..) adı verilen bir metod, (..) metodundan daha okunaklı bir şekilde okunabilir.
Bunu başka bir örnekle açıklayacağım. Diyelim ki bir kişiyi temsil eden bir Person varlığınız var. Kişinin bir firstName ve bir lastName özelliği vardır. Şimdi, bu sadece basit bir adres defteri olsaydı, kullanıcının bu bilgileri gerektiği gibi değiştirmesine izin verirsiniz ve setFirstName (..) ve setLastName (..) setter'lerini kullanabilirsiniz. Bununla birlikte, resmi bir devlet kayıt defteri oluşturuyorsanız, bir adı değiştirmek daha çok şey işin içine girer. ChangeName (firstName, lastName, reason, activeAsOfDate) gibi bir şeyle sonuçlanabilir. Yine, bağlam(context) her şeydir.
Getter'ler üzerine bir not:
Getter metodları Java'ya JavaBean specification'un bir parçası olarak eklendi . Bu belirtim Java'nın ilk sürümünde yoktu, bu nedenle standart Java API'sinde (örneğin String.getLength () yerine String.length ()) gibi spesifikasyona uymayan bazı metodlar bulabilirsiniz.
Şahsen benim için, Java'daki gerçek propertyler için şu açıdan destek görmek istiyorum. Sahne arkasında getter'lar ve setter'lar kullanıyor olsalar da, bir özellik değerine sadece sıradan bir alan gibi aynı şekilde erişmek istiyorum: mycontact.phoneNumber. Bunu henüz Java'da yapamıyoruz, ancak getter'lardan get ilk ekini bırakarak oldukça yaklaşabiliriz. Benim düşünceme göre, bu, özellikle bir şey almak için bir nesne hiyerarşisine daha derine inmeniz gerekiyorsa, kodu daha akıcı hale getirir: mycontact.address (). StreetNumber ().
Bununla birlikte, getter'lardan kurtulmanın bir dezavantajı da var ve bu da araç desteği. Tüm Java IDE'leri ve birçok libary JavaBean standardına dayanır, bu da sizin için otomatik olarak oluşturulmuş kodu elle yazabileceğiniz ve kurallara bağlı kalarak önlenebilecek ek açıklamalar ekleyebileceğiniz anlamına gelir.
Entity or Value Object?
(Varlık veta Değer Nesnesi)
Bir şeyin bir değer nesnesi mi yoksa bir varlık olarak mı modelleneceğini bilmek her zaman kolay değildir. Aynı gerçek dünya kavramı, bir bağlamda bir varlık olarak ve bir başka bağlamda bir değer nesnesi olarak modellenebilir. Örnek olarak street address'ini ele alalım.
Bir fatura sistemi oluşturuyorsanız, street address'i yalnızca faturada yazdırdığınız bir şeydir. Faturadaki metin doğru olduğu sürece hangi nesne örneğinin kullanıldığı önemli değildir. Bu durumda, street address'i bir değer nesnesidir.
Bir kamu hizmeti için bir sistem kuruyorsanız, belirli bir daireye hangi gaz hattının veya hangi elektrik hattının gittiğini tam olarak bilmeniz gerekir. Bu durumda, street address'i bir varlıktır ve hatta bina veya apartman gibi daha küçük varlıklara ayrılabilir.
Değişken olmamaları(immutable) ve küçük oldukları için değer nesneleriyle çalışmak daha kolaydır. Bu nedenle, az sayıda varlığa ve çok fazla değer nesnelere sahip bir tasarım hedeflemelisiniz.
KOD ÖRNEKLERİ
Java'daki bir Person varlığı böyle bir şeye benzeyebilir (kod test edilmemiştir ve netlik için bazı yöntem uygulamaları atlanmıştır):
Person.java
public class Person {
private final PersonId personId;
private final EventLog changeLog;
private PersonName name;
private LocalDate birthDate;
private StreetAddress address;
private EmailAddress email;
private PhoneNumber phoneNumber;
public Person(PersonId personId, PersonName name) {
this.personId = Objects.requireNonNull(personId);
this.changeLog = new EventLog();
changeName(name, "initial name");
}
public void changeName(PersonName name, String reason) {
Objects.requireNonNull(name);
this.name = name;
this.changeLog.register(new NameChangeEvent(name), reason);
}
public Stream getNameHistory() {
return this.changeLog.eventsOfType(NameChangeEvent.class).map(NameChangeEvent::getNewName);
}
// Other getters omitted
public boolean equals(Object o) {
if (o == this) {
return true;
}
if (o == null || o.getClass() != getClass()) {
return false;
}
return personId.equals(((Person) o).personId);
}
public int hashCode() {
return personId.hashCode();
}
}
Bu örnekte dikkat edilmesi gereken bazı noktalar:
- Varlık ID'si için bir değer nesnesi - PersonId - kullanılır. Bir UUID, bir String veya bir Long kullanabilirdik, ancak bir değer nesnesi hemen bunun belirli bir Person'u tanımlayan bir ID olduğunu söyler.
- Varlık kimliğine ek olarak, bu varlık birçok başka değer nesnesi de kullanır: PersonName, LocalDate (evet, bu standart Java API'sinin bir parçası olmasına rağmen bir değer nesnesidir), StreetAddress, EmailAddress ve PhoneNumber.
- Adı değiştirmek için bir setter kullanmak yerine, adın değiştirilme nedeninin yanı sıra, değişikliği bir olay günlüğünde de saklayan bir business metodu kullanırız.
- İsim değişikliklerinin geçmişini almak için bir getter var.
- equals ve hashCode yalnızca varlık ID'sini kontrol eder.
Domain-Driven Design and CRUD
(DDD ve CRUD İşlemleri)

- Ana görünüm, belki de filtreleme ve sıralama ile varlıkları arayabileceğiniz (alma(retrieve)) bir grid'den oluşur.
- Ana görünümde, yeni varlıklar oluşturmak için bir button vardır. Buttona tıklamak boş bir form getirir ve form gönderildiğinde, yeni varlık gridde görünür (oluştur (create)).
- Ana görünümde, seçilen objeyi düzenlemek için bir button bulunur. Düğmeye tıklandığında varlık verilerini içeren bir form açılır. Form gönderildiğinde, varlık yeni bilgilerle güncellenir (güncelleme(update)).
- Ana görünümde, seçilen varlığı silmek için bir button bulunur. Buttona tıklamak varlığı gridden siler (sil(delete)).
Bu modelin kesinlikle yazılım dünyasında yeri vardır, ancak DDD bir uygulamada norm yerine istisna olmalıdır. Nedeni şudur: CRUD uygulaması yalnızca verileri yapılandırmak, görüntülemek ve düzenlemekle ilgilidir. Normalde altta yatan business sürecini desteklemez. Bir kullanıcı sisteme bir şey girdiğinde, bir şeyi değiştirdiğinde veya bir şeyi kaldırdığında, bu kararın arkasında bir business nedeni vardır. Belki değişim daha büyük bir business sürecinin bir parçası olarak gerçekleşiyordur? Bir CRUD sisteminde, değişikliğin nedeni kaybolur ve business süreci kullanıcının sadece zihnindedir.
Gerçek bir DDD kullanıcı arabirimi, kendilerini ortak dilin (ve böylece DDD'nin) parçası olan eylemlere dayandırır ve iş süreçleri, kullanıcıların zihninin aksine sisteme yerleştirilir. Bu da, saf bir CRUD uygulamasından daha sağlam, ancak tartışmasız daha az esnek bir sisteme yol açar. Bu farkı bir karikatürsel bir örnekle açıklayacağım:
Şirket A, çalışanları yönetmek için DDD bir sisteme sahipken, Şirket B, CRUD güdümlü bir yaklaşıma sahiptir. Her iki şirkette de çalışan ayrılır. Bu durumda aşağıdakiler olur:
Şirket A:
- Yönetici, çalışanın sistemdeki kaydını arar.
- Yönetici 'İş Sözleşmesini Sonlandır' eylemini seçer.
- Sistem sonlandırma tarihini ve nedenini sorar.
- Yönetici gerekli bilgileri girer ve 'Sözleşmeyi Sonlandır' seçeneğini tıklatır.
- Sistem, çalışan kayıtlarını otomatik olarak günceller, çalışanın kullanıcı bilgilerini ve elektronik ofis anahtarını iptal eder ve bordro sistemine bir bildirim gönderir.
Şirket B:
- Yönetici, çalışanın sistemdeki kaydını arar.
- Yönetici, 'Sözleşme feshedildi' onay kutusuna bir onay işareti koyar ve fesih tarihini girer, ardından 'Kaydet'i tıklatır.
- Yönetici, kullanıcı yönetim sistemine giriş yapar, kullanıcının hesabına bakar, 'Devre dışı' onay kutusuna bir onay işareti ekler ve 'Kaydet'i tıklar.
- Yönetici, ofis anahtarı yönetim sisteminde oturum açar, kullanıcının anahtarını arar, 'Devre dışı' onay kutusuna bir onay işareti koyar ve 'Kaydet'i tıklar.
- Yönetici bordro departmanına çalışanın işten ayrıldığını bildiren bir e-posta gönderir.
Önemli çıkarımlar şunlardır: Tüm uygulamalar DDD tasarım için uygun değildir ve DDD bir uygulama yalnızca DDD bir backend'e değil aynı zamanda domain güdümlü bir kullanıcı arayüzüne sahiptir.
(Agregalar(Nesne Grupları))
Şimdi varlıkların ve değer nesnelerinin ne olduğunu bildiğimizde, bir sonraki önemli konsepte bakacağız: gruplar(agregalar). Agregalar, belirli özelliklere sahip bir varlık ve değer nesneleri grubudur:
- Agrega bir bütün olarak oluşturulur, alınır ve saklanır.
- Agrega daima tutarlı bir durumdadır.
- Agrega, ID'si agreganın kendisini tanımlamak için kullanılan agrega kökü(aggregate root) adı verilen bir varlığa(entity) aittir.

Ayrıca, agregalarle ilgili iki önemli kısıtlama vardır:
- Bir agregaya dışarıdan sadece köküne referans verilebilir. Agrega dışındaki nesneler, agrega içindeki herhangi bir başka varlığı referans gösteremez.
- Agrega kökü, agrega içinde business değişmezlerin(invariants) uygulanmasından sorumludur ve agreganın her zaman tutarlı bir durumda olmasını sağlar.

Bu, bir varlık tasarladığınızda, ne tür bir varlık yapacağınıza karar vermeniz gerektiği anlamına gelir. Varlık, bir aggregate kök gibi mi davranacak, aggregate kökün denetimi altında yaşayan local varlık(local entity) olarak adlandırdığım şey mi olacak? Local varlıklara toplamın dışından referans verilemediğinden, ID'lerinin aggregate içinde benzersiz olması (local bir kimliğe sahip olmaları) yeterlidir, oysa aggregate köklerin global olarak benzersiz ID'leri (global bir kimliğe sahip olmaları) gerekir. Ancak, bu semantik farkın önemi, aggregate'i nasıl saklayacağımıza bağlı olarak değişir. İlişkisel bir veritabanında, tüm varlıklar için aynı birincil anahtar oluşturma mekanizmasını kullanmak en mantıklıdır. Öte yandan, aggregate'in tamamı bir dokuman veritabanında tek bir belge olarak kaydedilirse, yerel varlıklar için gerçek local ID'lerinin kullanılması daha mantıklıdır.
Öyleyse bir varlığın aggregate kök olup olmadığını nasıl anlarsınız? Her şeyden önce, iki varlık arasında bir parent-child (veya master-detail) ilişkisi olması, parent'i otomatik olarak bir aggregate köke ve child'ı local bir varlığa dönüştürmez. Bu kararın verilebilmesi için daha fazla bilgiye ihtiyaç vardır. İşte bu noktada bu ayrımı nasıl yapmalıyız:
- Varlığa uygulamadan nasıl erişelecek?
- Varlık ID ile veya bir tür arama yoluyla aranacaksa, büyük olasılıkla bir aggregate köküdür.
- Diğer aggregate'ler varlığı referans alması gerekecek mi?
- Eğer varlığa diğer aggregatelerden referans verilecekse, kesinlikle bir aggregate köküdür.
- Uygulamada varlık nasıl değiştirilecek(modifiye edilecek)?
- Bağımsız olarak modifiye edilebilirse, muhtemelen bir aggregate köküdür.
- Başka bir varlıkta değişiklik yapılmadan değiştirilemezse, büyük olasılıkla local bir varlıktır.
Bir aggregate kök oluşturduğunuzu bildikten sonra, business değişmezlerini(invariants) zorla nasıl uygularsınız ve bu ne anlama geliyor? Bir business değişmezi, toplamda ne olursa olsun her zaman geçerli olması gereken bir kuraldır. Basit bir business değişkeni, bir faturada, toplam tutarın, öğelerin eklenmesine, düzenlenmesine veya kaldırılmasına bakılmaksızın her zaman satır öğelerinin tutarlarının toplamı olması olabilir. Değişmezler ortak dilin ve domain modelinin bir parçası olmalıdır.
Teknik olarak bir aggregate kök, business değişmezlerini farklı şekillerde zorlayabilir:
- Tüm durum değiştirme işlemleri aggregate kök üzerinden gerçekleştirilir.
- Local varlıklar üzerinde durum değiştirme işlemlerine izin verilir, ancak her değiştiğinde aggregate köke bildirir.
Bazı durumlarda, örneğin fatura toplamına sahip örnekte, değişmez, aggregate kök'e her istek yapıldığında toplamı dinamik olarak hesaplaması zorlanabilir.
Aggregatelerimi şahsen kendim tasarlarım, böylece değişmezler hemen ve her zaman uygulanır. Muhtemelen, aggregate kaydedilmeden önce yapılan sıkı veri doğrulaması yapılarak aynı sonucu elde edebilirsiniz (Java EE yolu). Günün sonunda, bu kişisel bir zevk meselesi.
Aggregate Design Guidelines
(Aggregate Tasarım Yönergeleri)
YÖNERGE 1: AGREGALARINIZI KÜÇÜK TUTUN
Agregalar her zaman bir bütün olarak alınır ve saklanır. Ne kadar az veri okumak ve yazmak zorunda kalırsanız, sisteminiz o kadar iyi performans gösterir. Aynı nedenle, zamanla büyüyebileceğinden, sınırsız one-to-many ilişkilerden (koleksiyonlar) kaçınmalısınız.
Agregadanızdaki local varlıklar (mutable) yerine değer nesnelerini (immutable) kullanmayı tercih eteseniz bilei küçük bir agregaya sahip olmak, agrega kökünün business değişmezlerinin kullanılmasını kolaylaştırır.
YÖNERGE 2: DİĞER AGREGALARA ID İLE REFERANS GÖSTERİN
Doğrudan başka bir aggreagete referans göstermek yerine, agrega kökü ID'sini saran bir değer nesnesi oluşturun ve bunu referans olarak kullanın. Bu, bir agregate'in durumunu yanlışlıkla bir diğerinin içinden değiştiremeyeceğiniz için toplam tutarlılık sınırlarının korunmasını kolaylaştırır. Ayrıca, toplu bir nesne alındığında derin nesne ağaçlarının veri deposundan alınmasını önler.

Doğrudan başka bir aggreagete referans göstermek yerine, agrega kökü ID'sini saran bir değer nesnesi oluşturun ve bunu referans olarak kullanın. Bu, bir agregate'in durumunu yanlışlıkla bir diğerinin içinden değiştiremeyeceğiniz için toplam tutarlılık sınırlarının korunmasını kolaylaştırır. Ayrıca, toplu bir nesne alındığında derin nesne ağaçlarının veri deposundan alınmasını önler.

Diğer agreganın verilerine gerçekten erişmeniz gerekiyorsa ve sorunu çözmenin daha iyi bir yolu yoksa, bu yönergeyi kırmanız gerekebilir. Persistance frameworke'ün lazy loading yeteneklerine güvenebilirsiniz, fakat deneyimlerime göre, çözdüklerinden daha fazla soruna neden olma eğilimindedirler. Daha fazla kodlama gerektiren ancak daha açık bir yaklaşım, repository'i bir metod parametresi olarak geçmektir:
public class Invoice extends AggregateRoot {
private CustomerId customerId;
// All the other methods and fields omitted
public void copyCustomerInformationToInvoice(CustomerRepository repository) {
Customer customer = repository.findById(customerId);
setCustomerName(customer.getName());
setCustomerAddress(customer.getAddress());
// etc.
}
}
YÖNERGE 3: TRNASACTION BAŞINA BİR AGREGA DEĞİŞTİRİN
İşlemlerinizi, tek bir transaction içinde yalnızca bir agregada değişiklik yapacak şekilde tasarlamaya çalışın. Birden çok agrega içeren işlemler için domain eventlerini ve nihai tutarlılığı kullanın (bunun hakkında daha fazla konuşacağız). Bu, istenmeyen yan etkileri önler ve gerekirse sistemin gelecekte distribute edilmesini kolaylaştırır. Ayrıca, document veritabanlarının transaction desteği olmadan kullanılmasını da kolaylaştırır.
Bununla birlikte, bu ek bir karmaşıklık maliyeti ile birlikte gelir.Domain eventlerini güvenilir bir şekilde işlemek için bir altyapı kurmanız gerekir. Özellikle aynı thread ve transaction içinde eşzamanlı olarak domain eventleri gönderebileceğiniz monolitik bir uygulamada, eklenen karmaşıklık nadiren motive olur. Bence iyi bir uzlaşma, diğer agregalarda değişiklik yapmak için domain eventlerine güvenmektir, ancak aynı transaction içinde yapmaktır:
Her durumda, bir agreganın durumunu doğrudan başka bir agreganın içinden değiştirmekten kaçınmalısınız.
Domain eventlerini ele aldığımızda bununla ilgili daha fazla tartışacağız.
YÖNERGE 4: OPTIMISTIC LOCKING KULLANIN
Agregaların temel özelliği, business değişmezlerini zorlamak ve veri tutarlılığını her zaman sağlamaktır. Agrega, çakışan veri depolama güncellemeleri nedeniyle bozulursa, bu durum boşuna olur. Bu nedenle, agregaları kaydederken veri kaybını önlemek için optimistic locking kullanmalısınız.
Optimistic locking'in pestimistic locking'e tercih edilmesinin nedeni, eğer persistence framework optimistic locking'i desteklemiyorsa bunu kendinizin gerçekleştirebilmesi ve distribute edilmesinin ve ölçeklendirmenin kolay olmasıdır.
Küçük agregalar (ve dolayısıyla küçük transactionlar) de çatışma riskini azalttığı için ilk yönergeye bağlı kalmak da bu konuda yardımcı olacaktır.
Agregalar, Değişmezler, Kullanıcı Arayüzü Bağlama ve Doğrulama
Bazılarınız büyük olasılıkla şimdi agregaların ve zorlayıcı iş değişmezlerinin kullanıcı arayüzleriyle birlikte nasıl çalıştıklarını ve daha spesifik olarak bağlayıcı oluşturduklarını merak ediyorsunuz. Değişmezler her zaman uygulanacaksa ve bir agreganın her zaman tutarlı bir durumda olması gerekiyorsa, kullanıcı formları doldururken ne yaparsınız? Ayrıca, setterlar yoksa, form alanlarını agregalara nasıl bağlarsınız?
Bununla baş etmenin birçok yolu vardır. En basit çözüm, agrega kaydedilene kadar değişmez zorlamayı ertelemek, tüm özellikler için setter'lar eklemek ve entityleri doğrudan forma bağlamaktır. Ben şahsen bu yaklaşımı sevmiyorum çünkü bu DDD olmaktan çok veri güdümlü olduğuna inanıyorum. Entitylerin, business logic'i bir hizmet katmanında (veya daha kötüsü, kullanıcı arayüzünde) sonuçlanacak şekilde anemik veri sahiplerine ayrılma riski yüksektir.
bkz : anemic domain model
Bunun yerine, diğer iki yaklaşımı tercih ediyorum. Birincisi, formları ve içeriklerini kendi domain modeli kavramlarına modellemektir. Gerçek dünyada, bir şey için başvurursanız, genellikle bir başvuru formu doldurmanız ve göndermeniz gerekir. Uygulama daha sonra işlenir ve gerekli tüm bilgiler sağlandıktan ve kurallara uyduğunuzda, uygulama çalışır ve başvurduğunuz her şeyi alırsınız. Domain modelinde bu işlemi taklit edebilirsiniz. Örneğin, Üyelik agrega kökü varsa, Üyelik oluşturmak için gereken tüm bilgileri toplamak için kullanılan bir MembershipApplication agrega köküne de sahip olabilirsiniz. Uygulama nesnesi daha sonra üyelik nesnesi oluşturulurken girdi olarak kullanılabilir.
İkinci yaklaşım birincinin bir varyantıdır ve essence pattern'idir. Düzenlemeniz gereken her varlık veya değer nesnesi için aynı bilgileri içeren değiştirilebilir(mutable) bir essence nesne oluşturun. Bu essence nesne daha sonra forma bağlanır. Essence nesnesi gerekli tüm bilgileri içerdikten sonra, gerçek varlıklar veya değer nesneleri oluşturmak için kullanılabilir. İlk yaklaşımın farkı, essence nesnelerin domain modelinin bir parçası olmaması, sadece gerçek domain nesneleriyle etkileşimi kolaylaştırmak için var olan teknik yapılardır. Pratikte, essence pattern böyle bir şeye benzeyebilir:
public class Person extends AggregateRoot {
private final DateOfBirth dateOfBirth;
// Rest of the fields omitted
public Person(String firstName, String lastName, LocalDate dateOfBirth) {
setDateOfBirth(dateOfBirth);
// Populate the rest of the fields
}
public Person(Person.Essence essence) {
setDateOfBirth(essence.getDateOfBirth());
// Populate the rest of the fields
}
private void setDateOfBirth(LocalDate dateOfBirth) {
this.dateOfBirth = Objects.requireNonNull(dateOfBirth, "dateOfBirth must not be null");
}
@Data // Lombok annotation to automatically generate getters and setters
public static class Essence {
private String firstName;
private String lastName;
private LocalDate dateOfBirth;
private String streetAddress;
private String postalCode;
private String city;
private Country country;
public Person createPerson() {
validate();
return new Person(this);
}
private void validate() {
// Make sure all necessary information has been entered, throw an exception if not
}
}
}
İsterseniz, bu kalıba daha aşina iseniz essence'i bir builder ile değiştirebilirsiniz. Sonuç aynı olurdu.
KOD ÖRNEKLERİ
Aşağıda, local ID'ye sahip bir agreaga kök (Order) ve bir local varlık (OrderItem) örneği verilmiştir (kod test edilmemiştir ve netlik için bazı metod uygulamaları atlanmıştır):
Order.java
public class Order extends AggregateRoot { // ID type passed in as generic parameter
private CustomerId customer;
private String shippingName;
private PostalAddress shippingAddress;
private String billingName;
private PostalAddress billingAddress;
private Money total;
private Long nextFreeItemId;
private List items = new ArrayList<>();
public Order(Customer customer) {
super(OrderId.createRandomUnique());
Objects.requireNonNull(customer);
// These setters are private and make sure the passed in parameters are valid:
setCustomer(customer.getId());
setShippingName(customer.getName());
setShippingAddress(customer.getAddress());
setBillingName(customer.getName());
setBillingAddress(customer.getAddress());
nextFreeItemId = 1L;
recalculateTotals();
}
public void changeShippingAddress(String name, PostalAddress address) {
setShippingName(name);
setShippingAddress(address);
}
public void changeBillingAddress(String name, PostalAddress address) {
setBillingName(name);
setBillingAddress(address);
}
private Long getNextFreeItemId() {
return nextFreeItemId++;
}
void recalculateTotals() { // Package visibility to make the method accessible from OrderItem
this.total = items.stream().map(OrderItem::getSubTotal).reduce(Money.ZERO, Money::add);
}
public OrderItem addItem(Product product) {
OrderItem item = new OrderItem(getNextFreeItemId(), this);
item.setProductId(product.getId());
item.setDescription(product.getName());
this.items.add(item);
return item;
}
// Getters, private setters and other methods omitted
}
public class OrderItem extends LocalEntity { // ID type passed in as generic parameter
private Order order;
private ProductId product;
private String description;
private int quantity;
private Money price;
private Money subTotal;
OrderItem(Long id, Order order) {
super(id);
this.order = Objects.requireNonNull(order);
this.quantity = 0;
this.price = Money.ZERO;
recalculateSubTotal();
}
private void recalculateSubTotal() {
Money oldSubTotal = this.subTotal;
this.subTotal = price.multiply(quantity);
if (oldSubTotal != null && !oldSubTotal.equals(this.subTotal)) {
this.order.recalculateTotals(); // Invoke aggregate root to enforce invariants
}
}
public void setQuantity(int quantity) {
if (quantity < 0) {
throw new IllegalArgumentException("Quantity cannot be negative");
}
this.quantity = quantity;
recalculateSubTotal();
}
public void setPrice(Money price) {
Objects.requireNonNull(price, "price must not be null");
this.price = price;
recalculateSubTotal();
}
// Getters and other setters omitted
}
Domain Events
(Domain Olayları)
Şimdiye kadar yalnızca domain modelindeki "şeylere" baktık. Bununla birlikte, bunlar sadece modelin herhangi bir anda bulunduğu statik durumu tanımlamak için kullanılabilir. Birçok iş modelinde, gerçekleşen şeyleri tanımlamanız ve modelin durumunu değiştirebilmeniz gerekir. Bunun için domain eventlerini kullanabilirsiniz.
Domain eventleri Evans'ın DDD hakkındaki kitabına dahil edilmedi. Araç kutusuna daha sonra eklendi ve Vernon’un kitabına dahil edildi.
Bir domain eventi, domain modelinde, sistemin diğer bölümlerini ilgilendirebilecek herhangi bir şeydir. Domain eventleri, kaba taneli(coarse-grained) (ör. Belirli bir agrega kök oluşturulur veya bir işlem başlatılır) veya ince taneli(fine-grained) (ör. Belirli bir agrega kökün belirli bir özniteliği değiştirilir) olabilir.
- Domain eventleri genellikle aşağıdaki özelliklere sahiptir:
- Değişmezler(Immutable) (sonuçta geçmişi değiştiremezsiniz).
- Söz konusu olay gerçekleştiğinde zaman damgası(timestamp) vardır.
- Bir etkinliği diğerinden ayırt etmeye yardımcı olan benzersiz bir kimliğe(ID) sahip olabilirler.Bu, olayın türüne ve olayın nasıl dağıtıldığına bağlıdır.
- Agrega kökler veya domain servisleri(daha sonra hakkında daha fazla bilgi vereceğiz) tarafından yayınlanır.
Bir domain eventi yayınlandıktan sonra, bir veya daha fazla domain eventi dinleyicisi tarafından alınabilir ve bu da ek işleme ve yeni domain eventlerini tetikleyebilir. Yayıncı, eventin ne olduğunun farkında değildir ve dinleyici de yayıncıyı etkileyemez (diğer bir deyişle, domain eventlerini yayınlamak yayıncının bakış açısından yan etki içermemelidir). Bu nedenle, domain event dinleyicilerinin eventi yayımlayan ile aynı işlem içinde çalıştırılmaması önerilir.
Tasarım açısından bakıldığında, domain eventlerinin en büyük avantajı sistemi genişletilebilir hale getirmeleridir. Mevcut kodu değiştirmek zorunda kalmadan yeni iş mantığını tetiklemek için ihtiyaç duyduğunuz sayıda domain event dinleyicisi ekleyebilirsiniz. Bu doğal olarak doğru eventlerin ilk etapta yayınlandığını varsayar. Bazı eventlerin önceden farkında olabilirsiniz, ancak diğerleri kendilerini yolda daha fazla gösterecektir. Elbette, ne tür eventlere ihtiyaç duyulacağını tahmin etmeye ve bunları modelinize eklemeye çalışabilirsiniz, ancak daha sonra hiçbir yerde kullanılmayan domain eventleriyle sistemi tıkama riski de vardır. Daha iyi bir yaklaşım, domain eventlerini yayınlamayı mümkün olduğunca kolaylaştırmak ve daha sonra bunlara ihtiyacınız olduğunu fark ettiğinizde eksik eventleri eklemektir.
Event Kaynaklarına İlişkin Not
Event kaynağı, bir sistemin durumunun düzenli bir event günlüğü olarak devam ettiği bir tasarım modelidir. Her biri sistemin durumunu değiştirir ve mevcut durum, event günlüğünü baştan sona tekrar oynatarak herhangi bir zamanda hesaplanabilir. Bu örüntü, özellikle tarihin mevcut durum kadar önemli (hatta daha önemli) olduğu finansal defterler veya tıbbi kayıtlar gibi uygulamalarda kullanışlıdır.
Deneyimlerime göre, tipik bir iş sisteminin çoğu bölümü event kaynağı gerektirmez, ancak bazı bölümleri gerektirir. Tüm sistemi event kaynağı oluşturmayı bir kalıcılık modeli olarak kullanmaya zorlamak, bence, aşırıya kaçmak olacaktır. Ancak, domain eventlerinin gerektiğinde event kaynağı oluşturmak için kullanılabileceğini buldum. Uygulamada, bu, modelin durumunu değiştiren her işlemin, bazı event günlüğünde depolanan bir domain eventi de yayınlayacağı anlamına gelir. Bunun teknik olarak nasıl yapılacağı bu yazının kapsamı dışındadır.
Domain Eventlerini Dağıtma
Domain eventleri yalnızca bunları dinleyicilere dağıtmanın güvenilir bir yoluna sahipseniz kullanılabilir. Bir monolitin içinde, standart observer desenini kullanarak bellek içi dağılımı işleyebilirsiniz. Ancak, bu durumda bile, event yayıncılarını ayrı transactionlarda çalıştırmanın en iyi yöntemlerini izlerseniz daha karmaşık bir şeye ihtiyacınız olabilir. Event dinleyicilerinden biri başarısız olursa ve event yeniden gönderilirmesi gerekirse ne olur?
Vernon, hem uzaktan hem de local olarak çalışan eventleri dağıtmanın iki farklı yolunu sunar. Detaylar için kitabını okumanızı tavsiye ederim ama buradaki seçeneklerin kısa bir özetini vereceğim.
MESAJ KUYRUĞU İLE DAĞITIM
Bu çözüm, AMQP veya JMS gibi harici bir mesajlaşma çözümü (MQ) gerektirir. Çözüm, publish-subscribe modelini ve garantili teslimatı desteklemelidir. Bir domain eventi yayınlandığında, publisher eventi MQ'ya gönderir. Domain event dinleyicileri MQ'ya abone olur ve hemen bilgilendirilir.

Bu modelin avantajları, hızlı, uygulanması oldukça kolay ve mevcut denenmiş ve gerçek mesajlaşma çözümlerine güvenmesidir. Dezavantajları, MQ çözümünü kurmanız ve sürdürmeniz gerektiğidir ve yeni bir tüketici abone olursa geçmiş olayları almanın bir yolu yoktur.
EVENT LOG İLE DAĞILIMI
Bu çözüm ek bileşen gerektirmez, ancak kodlama gerektirir. Bir domain eventi yayınlandığında, log'a eklenir. Domain event dinleyicileri, yeni eventleri kontrol etmek için bu logu düzenli olarak yoklar. Ayrıca, her seferinde tüm logu gözden geçirmek zorunda kalmamak için zaten hangi eventleri işlediklerini takip ederler.
Bu modelin avantajları, herhangi bir ek bileşen gerektirmemesi ve yeni event dinleyicileri için tekrarlanabilen eksiksiz bir olay geçmişi içermesidir. Dezavantajı, uygulanması için biraz çalışma gerektirmesi ve bir dinleyici tarafından yayınlanan ve alınan bir event arasındaki gecikmenin en çok yoklama aralığında olmasıdır.
Nihai Tutarlılık Üzerine Bir Not
Veri tutarlılığı, dağıtılmış sistemlerde veya aynı mantıksal transactionda birden fazla veri deposunun yer aldığı bir sorundur. Gelişmiş uygulama sunucuları, bu sorunu çözmek için kullanılabilen dağıtılmış işlemleri destekler, ancak özel yazılım gerektirirler ve yapılandırılması ve bakımı karmaşık işler olabilir. Güçlü tutarlılık mutlak bir gereklilikse, dağıtılmış transactionları kullanmaktan başka seçeneğiniz yoktur, ancak birçok durumda güçlü tutarlılığın aslında bir iş açısından o kadar da önemli olmadığı ortaya çıkabilir. Biz sadece tek bir ACID transactionunda tek bir veritabanı ile konuşan tek bir uygulamamız olduğu zamanlardan beri güçlü tutarlılık açısından düşünmeye alışkınız.
Güçlü tutarlılığın alternatifi nihai tutarlılıktır. Bu, uygulamadaki verilerin nihayetinde tutarlı hale geleceği anlamına gelir, ancak sistemin tüm bölümlerinin birbiriyle senkronize olmadığı ve mükemmel derecede iyi olduğu zamanlar olacaktır. Nihai tutarlılık için bir uygulama tasarlamak farklı bir düşünme yöntemi gerektirir, ancak bunun karşılığında, yalnızca güçlü tutarlılık gerektiren bir sistemden daha esnek ve ölçeklenebilir bir sistem elde edilebilir.
DDD bir sistemde domain eventleri, nihai tutarlılığa ulaşmanın mükemmel bir yoludur. Başka bir modülde veya sistemde bir şey olduğunda kendini güncellemesi gereken herhangi bir sistem veya modül, o sistemden gelen domain eventlerine abone olabilir:

Yukarıdaki örnekte, Sistem A'da yapılan değişiklikler sonundadomain eventleri aracılığıyla B, C ve D sistemlerine yayılacaktır. Her sistem veri deposunu güncellemek için kendi yerel transactionlarını kullanacaktır. Olay dağıtım mekanizmasına ve sistemlerin yüküne bağlı olarak, yayılma süresi bir saniyeden az olabilir (tüm sistemler aynı ağda çalışır ve olaylar derhal abonelere gönderilir) ila birkaç saat hatta gün (bazılarının sistemler çevrimdışıdır ve yalnızca son check-in işleminden bu yana gerçekleşen tüm domain eventlerini indirmek için ağa zaman zaman bağlanır).
Nihai tutarlılığı başarıyla uygulamak için, bir event ilk kez yayınlandığında abonelerin bazıları şu anda çevrimiçi olmasa bile çalışan domain eventlerini dağıtmak için güvenilir bir sisteme sahip olmanız gerekir. Ayrıca, herhangi bir veri parçasının bir süre için out of date olabileceği varsayımı çerçevesinde hem iş mantığınızı hem de kullanıcı arayüzünüzü tasarlamanız gerekir. Ayrıca, verilerin ne kadar tutarsız olabileceğine dair kısıtlamalar oluşturmanız gerekir. Bazı veri parçalarının günlerce tutarsız kalabildiğini görmek sizi şaşırtabilirken, diğer veri parçalarının saniyeler içinde veya daha kısa bir sürede güncellenmesi gerekir.
KOD ÖRNEKLERİ
Aşağıda, sipariş gönderildiğinde bir domain eventi (OrderShipped) yayınlayan bir agrega kök (Order) örneği verilmiştir. Bir domain dinleyicisi (InvoiceCreator) eventi alır ve ayrı bir işlemde yeni bir fatura oluşturur. Agrega kök kaydedildiğinde kayıtlı tüm eventleri yayınlayan bir mekanizma olduğu varsayılmaktadır (kod test edilmemiştir ve netlik için bazı yöntem uygulamaları atlanmıştır):
OrderShipped.java
public class OrderShipped implements DomainEvent {
private final OrderId order;
private final Instant occurredOn;
public OrderShipped(OrderId order, Instant occurredOn) {
this.order = order;
this.occurredOn = occurredOn;
}
// Getters omitted
}
public class Order extends AggregateRoot{ // Other methods omitted public void ship() { // Do some business logic registerEvent(new OrderShipped(this.getId(), Instant.now())); } }
public class InvoiceCreator {
final OrderRepository orderRepository;
final InvoiceRepository invoiceRepository;
// Constructor omitted
@DomainEventListener
@Transactional
public void onOrderShipped(OrderShipped event) {
var order = orderRepository.find(event.getOrderId());
var invoice = invoiceFactory.createInvoiceFor(order);
invoiceRepository.save(invoice);
}
}
Hareketli ve Statik Nesneler
Devam etmeden önce, sizi hareketli ve statik nesnelere tanıtmak istiyorum. Bunlar gerçek DDD terimleri değil, domain modelinin farklı bölümlerini düşündüğümde kendim kullandığım bir şey. Benim dünyamda, taşınabilir bir nesne, birden fazla örneği olabilen ve uygulamanın farklı bölümleri arasında geçirilebilen herhangi bir nesnedir. Değer nesneleri, varlıklar ve domain eventlerinin tümü taşınabilir nesnelerdir.
Öte yandan, statik bir nesne, her zaman tek bir yerde duran ve uygulamanın diğer bölümleri tarafından çağrılan ancak nadiren (diğer statik nesnelere enjekte edilenler hariç) geçirilen singleton (veya pooled bir kaynak) 'tır. Repositoryler, domain servisleri ve factorylerin tümü statik nesnelerdir.
Bu fark önemlidir çünkü nesneler arasında ne tür ilişkileriniz olabileceğini belirler. Statik nesneler, diğer statik nesnelere ve taşınabilir nesnelere referans tutabilir.
Taşınabilir nesneler, diğer hareketli nesnelerin referansını tutabilir. Ancak, hareketli bir nesne hiçbir zaman statik bir nesneye başvuru yapamaz. Taşınabilir bir nesnenin statik bir nesneyle etkileşime girmesi gerekiyorsa, statik nesnenin kendisiyle etkileşime girecek metoda bir metod parametresi olarak iletilmesi gerekir. Bu, taşınabilir nesneleri daha taşınabilir ve bağımsız bir hale getirir, çünkü her seferinde deserialize ettiğimizde statik nesnelere herhangi bir referansa bakmanız ve enjekte etmeniz gerekmez.
Diğer Domain Nesneleri
DDD kodla çalışırken, bir sınıfın değer nesnesine, varlık veya domain event kalıbına gerçekten uymadığı durumlarda karşılaşacağınız zamanlar olacaktır. Deneyimlerime göre, bu genellikle aşağıdaki durumlarda olur:
- Harici bir sistemden herhangi bir bilgi (= başka bir sınırlı bağlam(bounded context)). Bilgiler sizin bakış açınızdan değiştirilemez, ancak benzersiz bir şekilde tanımlamak için kullanılan bir global ID'ye sahiptir.
- Diğer varlıkları tanımlamak için kullanılan verileri yazın (Vaughn Vernon, bu nesnelere standart tipler olarak adlandırır). Bu nesneler global ID'lere sahiptir ve bir dereceye kadar değişebilir olabilir, ancak uygulamanın kendisinin tüm pratik amaçları için değişmezdirler(immutable).
- Denetim girişlerini veya domain eventlerini veritabanında depolamak için kullanılan altyapı altyapı - framework düzeyindeki varlıklar. Global ID'leri olabilir veya olmayabilir ve kullanım durumuna bağlı olarak değişebilir(mutable) veya değişmeyebilir(immutable).
Bu durumları ele almanın yolu, DomainObject adı verilen bir şeyle başlayan temel sınıflar ve arabirimler hiyerarşisini kullanmaktır. Domain nesnesi, bir şekilde domain modeliyle ilgili olan herhangi bir hareketli nesnedir. Bir nesne tamamen bir değer nesnesiyse veya tamamen bir varlık değilse, bunu bir domain nesnesi olarak tanımlayabilirim ve JavaDocs'ta ne yaptığını ve nedenini açıklayabilir ve devam edebilirim.
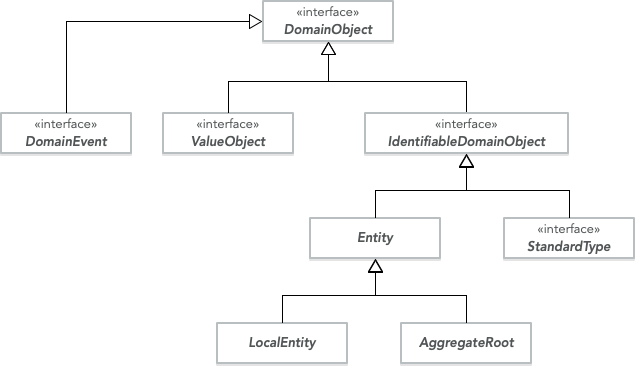
Arabirimleri hiyerarşinin en üstünde kullanmayı seviyorum çünkü bunları istediğiniz şekilde birleştirebilir ve hatta enum'ların bunları uygulamasını sağlayabilirsiniz. Arabirimlerin bazıları, yalnızca uygulayıcı sınıfın domain modelinde hangi rolü oynadığını göstermek için kullanılan herhangi bir metod içermeyen işaretleyici arabirimleridir. Yukarıdaki şemada, sınıflar ve arayüzler aşağıdaki gibidir:
DomainObject - tüm domain nesneleri için en üst düzey işaretleyici arabirimi.
DomainEvent - tüm domain event'leri için arabirim. Bu genellikle event hakkında eventin tarihi ve saati gibi bazı meta veriler içerir, ancak bir işaretleyici arayüzü de olabilir.
ValueObject - tüm değer nesneleri için işaretleyici arabirimi. Bu arayüzün uygulamalarının değişmez olması ve equals () ve hashCode () yöntemlerinin uygulanması gerekir. Ne yazık ki, güzel olsa da, bunu arayüz seviyesinden zorlamanın bir yolu yoktur.
IdentifiableDomainObject - bir bağlamda(context) benzersiz olarak tanımlanabilen tüm domain nesneleri için arabirim. Genellikle bunu genel bir parametre olarak ID türü ile genel bir arayüz olarak tasarlarım.
StandardType - standart tipler için işaretleyici arabirimi.
Entity - varlıklar için soyut temel sınıf. Ben genellikle ID için bir alan eklerim ve buna göre equals () ve hashCode () uygularım. Persistence framework'e bağlı olarak bu sınıfa optimistic locking bilgisi de ekleyebilirim.
LocalEntity - yerel varlıklar için soyut temel sınıf. Yerel varlıklar için yerel kimlik kullanırsam, bu sınıf bunu yönetmek için kod içerecektir. Aksi takdirde, sadece boş bir işaretleyici sınıfı olabilir.
AggregateRoot - agrega kökleri için soyut temel sınıf. Local varlıklar için local kimlik kullanırsam, bu sınıf yeni local kimlikler oluşturmak için kod içerecektir. Sınıf ayrıca domain eventlerini göndermek için kod içerecektir. Varlık sınıfına optimistic locking bilgileri dahil edilmemişse, kesinlikle buraya dahil edilir. Denetim bilgileri (yaratılan, son güncellenen vb.), uygulamanın gereksinimlerine bağlı olarak bu sınıfa da eklenebilir.
KOD ÖRNEKLERİ
Bu kod örneğinde, iki sınırlı bağlamımız(bounded context) var: kimlik yönetimi ve çalışan yönetimi:

Çalışan yönetimi bağlamının kimlik yönetim bağlamından kullanıcılar hakkında hepsi olmasa da bazı bilgilere ihtiyacı vardır. Bunun için bir REST endpoint vardır ve veriler JSON'a serialize edilir.
Kimlik yönetimi bağlamında bir Kullanıcı şu şekilde temsil edilir:
User.java (identity management)
User.java (identity management)
public class User extends AggregateRoot {
private String userName;
private String firstName;
private String lastName;
private Instant validFrom;
private Instant validTo;
private boolean disabled;
private Instant nextPasswordChange;
private List passwordHistory;
// Getters, setters and business logic omitted
}
Çalışan yönetimi bağlamında, yalnızca kullanıcı ID'sne ve adına ihtiyacımız var. Kullanıcı ID ile benzersiz bir şekilde tanımlanır, ancak ad kullanıcı arayüzünde gösterilir. Açıkçası herhangi bir kullanıcı bilgisini değiştiremeyiz, böylece kullanıcı bilgileri değiştirilemez. Kod şöyle görünür:
User.java (employee management)
public class User implements IdentifiableDomainObject {
private final UserId userId;
private final String firstName;
private final String lastName;
@JsonCreator // We can deserialize the incoming JSON directly into an instance of this class.
public User(String userId, String firstName, String lastName) {
// Populate fields, convert incoming userId string parameter into a UserId value object instance.
}
public String getFullName() {
return String.format("%s %s", firstName, lastName);
}
// Other getters omitted.
public boolean equals(Object o) {
// Check userId only
}
public int hashCode() {
// Calculate based on userId only
}
}
Repositories
Artık domain modelinin tüm hareketli nesnelerini ele aldık ve artık statik olanlara geçme zamanı. İlk statik nesne repository'dir. Bir repository, agregaların peristence konteynırıdır. Bir repository'e kaydedilen tüm agregalar, sistem yeniden başlatıldıktan sonra bile daha sonra oradan alınabilir.
Bir repository'nin en azından aşağıdaki yetenekleri olmalıdır:
- Bir tür veri depolamada bir agregayı tamamen kaydetme yeteneği.
- Bir agregayı, ID'sine göre bütünüyle alabilme.
- Bir agregayo ID'sine göre tamamen silme yeteneği.
Çoğu durumda, gerçekten kullanılabilir olmak için, bir repository'nin daha gelişmiş query yöntemlerine de ihtiyacı vardır.
Pratikte, bir repository, ilişkisel veritabanı, NoSQL veritabanı, dizin hizmeti veya hatta dosya sistemi gibi harici bir veri depolama alanına domainin farkında olan bir arabirimdir. Gerçek depolama repository'nin arkasında gizlenmiş olsa da, depolama semantiği tipik olarak sızıntı yapacak ve repository'nin neye benzemesi gerektiği konusunda sınırlar getirecektir. Bu nedenle, repository'ler tipik olarak collection-oriented veya persistence-oriented'dır.
Collection oriented bir repository, bellek içi bir nesne koleksiyonunu taklit etmeyi amaçlamaktadır. Bir agrega koleksiyona eklendikten sonra, agrega repository'den kaldırılana kadar üzerinde yapılan değişiklikler otomatik olarak devam eder. Başka bir deyişle, koleksiyon odaklı bir repository add () ve remove () gibi yöntemlere sahip olacak, ancak kaydetmek için herhangi bir metod bulunmayacaktır.
Persistence oriented bir repository ise bir koleksiyonu taklit etmeye çalışmaz. Bunun yerine, harici bir kalıcı çözüm için bir facede görevi görür ve insert (), update () ve delete () gibi metodlar içerir. Toplamda yapılan herhangi bir değişikliğin, bir update () metoduna yapılan çağrı yoluyla açıkça depoya kaydedilmesi gerekir.
Anlamsal olarak oldukça farklı oldukları için repository türünün projenin başında doğru olması önemlidir. Genellikle, kalıcılığa yönelik bir repository'nin uygulanması daha kolaydır ve mevcut persistence frameworklerin çoğuyla çalışır. Koleksiyona dayalı bir repository'nin altında yatan persistence framework onu ortaya çıkarmadıkça uygulanması daha zordur.
KOD ÖRNEKLERİ
Bu örnek, collection oriented ve persistence oriented repository'ler arasındaki farkları gösterir.
Collection-oriented repository
public interface OrderRepository {
Optional get(OrderId id);
boolean contains(OrderID id);
void add(Order order);
void remove(Order order);
Page search(OrderSpecification specification, int offset, int size);
}
// Would be used like this:
public void doSomethingWithOrder(OrderId id) {
orderRepository.get(id).ifPresent(order -> order.doSomething());
// Changes will be automatically persisted.
}
Persistence oriented repository
public interface OrderRepository {
Optional findById(OrderId id);
boolean exists(OrderId id);
Order save(Order order);
void delete(Order order);
Page findAll(OrderSpecification specification, int offset, int size);
}
// Would be used like this:
public void doSomethingWithOrder(OrderId id) {
orderRepository.findById(id).ifPresent(order -> {
order.doSomething();
orderRepository.save(order);
});
}
CQRS Hakkında Bir Not
Repository'ler her zaman agregaları kaydeder ve alır. Bu, nasıl uygulandıklarına ve her bir agrega için oluşturulması gereken nesne grafiklerinin boyutuna bağlı olarak oldukça yavaş olabileceği anlamına gelir. Bu, UX açısından sorunlu olabilir ve özellikle iki kullanım durumu akla gelir. Birincisi, yalnızca bir veya iki özellik kullanarak agrega listesini göstermek istediğiniz küçük bir listedir. Yalnızca birkaç öznitelik değerine ihtiyacınız olduğunda eksiksiz bir nesne grafiği oluşturmak zaman kaybı ve bilgi işlem kaynaklarıdır ve genellikle yavaş bir kullanıcı deneyimine yol açar. Başka bir durum, bir listede tek bir öğeyi göstermek için birden fazla agregadaki verileri birleştirmeniz gerektiğidir. Bu, daha kötü performansa neden olabilir.
Veri setleri ve agregalar küçük olduğu sürece, performans kaybı kabul edilebilir, ancak performansın kabul edilebilir olmadığı zaman gelirse bir çözüm vardır: Komut Sorgu Sorumluluk Ayrımı (Command Query Responsibility Segregation)(CQRS).
CQRS, yazma (komutlar) ve okuma (sorgular) işlemlerini birbirinden tamamen ayırdığınız bir modeldir. Detaylara girmek bu yazının kapsamı dışındadır, ancak DDD açısından, deseni şu şekilde uygularsınız:
- Sistemin durumunu değiştiren tüm kullanıcı işlemleri repository'lerden normal şekilde geçer.
- Tüm sorgular repository'leri atlar ve doğrudan temel alınan veritabanına gider ve yalnızca gerekli verileri alır ve başka bir şey almaz.
- Gerekirse, kullanıcı arayüzündeki her görünüm için ayrı sorgu nesneleri bile tasarlayabilirsiniz
- Sorgu nesneleri tarafından döndürülen Veri Aktarım Nesneleri (DTO), agrega ID'lerini içermelidir, böylece değişiklik yapma zamanı geldiğinde doğru agrega repository'den alınabilir.
Birçok projede, bazı görünümlerde CQRS'yi ve diğerlerinde doğrudan repository sorgularını kullanabilirsiniz.
Hem değer nesnelerinin hem de varlıkların iş mantığı içerebileceğini (ve içermesi gerektiğini) daha önce belirtmiştik. Bununla birlikte, bir mantığın belirli bir değer nesnesine veya belirli bir varlığa uymadığı senaryolar vardır. İş mantığını yanlış yere koymak kötü bir fikirdir, bu yüzden başka bir çözüme ihtiyacımız var. İkinci statik nesnesimizi: domain servisi.
Domain servisleri aşağıdaki özelliklere sahiptir:
- Durum bilgisi tutmazlar(stateless)
- Son derece cohesive'lerdir (yani sadece bir şey yapmakta uzmanlaşmışlardır)
- Başka bir yerde doğal olarak uymayan iş mantığı içerirler.
- Diğer domain servisleriyle ve bir ölçüde repository'lerle etkileşime girebilirler.
- Domain event'lerini yayınlayabilirler.
En basit haliyle, bir domain servisi, içinde statik bir metod bulunan bir utility sınıfı olabilir. Daha gelişmiş domain servisleri diğer domain serrvislerinin ve repositorylerin bunlara enjekte edildiği singleton öğeler olarak uygulanabilir.
Bir domain servis bir uygulama servisiyle karıştırılmamalıdır. Bu serinin bir sonraki makalesinde uygulama servislerine daha yakından bakacağız, ancak kısacası, bir uygulama servisi, yalıtılmış domain modeli ile dünyanın geri kalanı arasındaki orta insan gibi davranır. Uygulama servisi, transactionların gerçekleştirilmesinden, sistem güvenliğinin sağlanmasından, uygun agregaların aranmasından, bunlara metod çağrılmasından ve değişiklikleri veritabanına geri kaydedilmesinden sorumludur. Uygulama servisleri herhangi bir iş mantığı içermez.
Uygulama ve domain servisleri arasındaki farkı şu şekilde özetleyebilirsiniz: bir domain servisi yalnızca iş kararları vermekten sorumluyken, bir uygulama servisi yalnızca orkestrasyondan sorumludur (doğru nesneleri bulmak ve doğru metodları doğru sırayla çağırmak). Bu nedenle, bir domain servisi genellikle veritabanının durumunu değiştiren herhangi bir repository'i çağırmamalıdır - bu, uygulama servisinin sorumluluğundadır.
KOD ÖRNEKLERİ
Bu ilk örnekte, belirli bir parasal işlemin devam etmesine izin verilip verilmediğini kontrol eden bir domain servisi oluşturacağız. Uygulama büyük ölçüde basitleştirilmiştir, ancak önceden tanımlanmış bazı iş kurallarına dayanarak açıkça bir iş kararı vermektedir.
Bu durumda, iş mantığı çok basit olduğu için, bunu doğrudan Account sınıfına ekleyebilirsiniz. Bununla birlikte, daha gelişmiş iş kuralları yürürlüğe girer girmez, karar vermeyi kendi sınıfına taşımak mantıklıdır (özellikle kurallar zaman içinde değişir veya bazı dış yapılandırmalara bağlıysa). Bu mantığın domain servisibe ait olabileceğine dair bir başka işaret, birden fazla toplama (iki hesap) içermesidir.
TransactionValidator.java
public class TransactionValidator {
public boolean isValid(Money amount, Account from, Account to) {
if (!from.getCurrency().equals(amount.getCurrency())) {
return false;
}
if (!to.getCurrency().equals(amount.getCurrency())) {
return false;
}
if (from.getBalance().isLessThan(amount)) {
return false;
}
if (amount.isGreaterThan(someThreshold)) {
return false;
}
return true;
}
}
İkinci örnekte, özel bir özelliğe sahip bir domain servisibe bakacağız: arabirimi domain modelinin bir parçasıdır, ancak uygulaması değildir. Bu, domain modelinizde bir iş kararı vermek için dış dünyadan bilgiye ihtiyaç duyduğunuzda ortaya çıkabilecek bir durumdur, ancak bu bilgilerin nereden geldiğiyle ilgilenmezsiniz.
CurrencyExchangeService.java
public interface CurrencyExchangeService {
Money convertToCurrency(Money currentAmount, Currency desiredCurrency);
}
Domain modeli, örneğin bir dependency injection framework kullanılarak bağlandığında, bu arabirimin doğru uygulamasını enjekte edebilirsiniz. Local cache çağıran bir servvise, veya uzak bir web servisi çağıran bir servise sahip olabilirsiniz; bir diğeri yalnızca test amacıyla kullanılıabilir vb.
Factories
Görüneceğimiz son statik nesne factory. Adından da anlaşılacağı gibi, factoryler yeni agregalar oluşturmaktan sorumludur. Ancak bu, her bir agrega için yeni bir fabrika oluşturmanız gerektiği anlamına gelmez. Çoğu durumda, agrega kökün yapıcısı, agaregayı tutarlı bir durumda olacak şekilde ayarlamak için yeterli olacaktır. Aşağıdaki durumlarda genellikle ayrı bir factory'e ihtiyacınız olacaktır:
- İş mantığı agreganın oluşturulmasında rol oynar
- Agregatın yapısı ve içeriği giriş verilerine bağlı olarak çok farklı olabilir
- Giriş verileri o kadar geniştir ki, oluşturucu modeli (veya benzer bir şey) gereklidir
- Factory, sınırlı bir bağlamdan(bounded context) diğerine çeviri yapar.
Factory, agrega kök sınıfında statik bir factory metodu veya ayrı bir factory sınıfı olabilir. Factory diğer factorylerle, repositorylerle ve domain servisleriyle etkileşime girebilir ancak veritabanının durumunu asla değiştirmemelidir (bu nedenle kaydetme veya silme işlemi yapılmaz).
KOD ÖRNEKLERİ
Bu örnekte, iki sınırlı bağlam(bounded context) arasında çeviri yapan bir fabrikaya bakacağız. Sevkiyat bağlamında müşteriye artık müşteri olarak değil, gönderi alıcısı olarak atıfta bulunulur. Gerekirse iki kavramı daha sonra ilişkilendirebilmemiz için müşteri ID'si hala saklanabilir.
ShipmentRecipientFactory.java
public class ShipmentRecipientFactory {
private final PostOfficeRepository postOfficeRepository;
private final StreetAddressRepository streetAddressRepository;
// Initializing constructor omitted
ShipmentRecipient createShipmentRecipient(Customer customer) {
var postOffice = postOfficeRepository.findByPostalCode(customer.postalCode());
var streetAddress = streetAddressRepository.findByPostOfficeAndName(postOffice, customer.streetAddress());
var recipient = new ShipmentRecipient(customer.fullName(), streetAddress);
recipient.associateWithCustomer(customer.id());
return recipient;
}
}
(Modüller)
Bir sonraki makaleye geçme zamanı geldi, ancak taktiksel DDD tasarımdan ayrılmadan önce, bakmamız gereken bir kavram daha var ve bu da modüller.
DDD'deki modüller Java'daki paketlere ve C # 'daki namespace'lere karşılık gelir. Bir modül sınırlı bir bağlama(bounded context) karşılık gelebilir, ancak tipik olarak sınırlı bir bağlamda birden fazla modül bulunur.
Birbirine ait sınıflar aynı modüle gruplanmalıdır. Ancak, sınıf türüne göre değil, sınıfların iş perspektifinden domain modeline nasıl uyduğuna bağlı olarak modüller oluşturmalısınız. Yani, tüm repositoryleri bir modüle, tüm varlıkları diğerine vb. koymamalısınız. Bunun yerine, belirli bir agrega veya belirli bir iş süreci ile ilgili tüm sınıfları aynı modüle koymalısınız. Bu, birlikte ait ve birlikte çalışan sınıflar da birlikte yaşadığından kodunuzda gezinmeyi kolaylaştırır.
Modül Örneği
Bu, sınıfları türe göre gruplayan bir modül yapısına örnektir. Bunu yapmayın:
- foo.bar.domain.model.services
AuthenticationServicePasswordEncoder- foo.bar.domain.model.repositories
UserRepositoryRoleRepository- foo.bar.domain.model.entities
UserRole- foo.bar.domain.model.valueobjects
UserIdRoleIdUserName
- foo.bar.domain.model.authentication
AuthenticationService- foo.bar.domain.model.user
UserUserRepositoryUserIdUserNamePasswordEncoder- foo.bar.domain.model.role
RoleRoleRepositoryRoleId
Bu serinin ilk makalesinin girişinde bahsettiğim gibi, öncelikle ciddi veri tutarsızlığı sorunlarından muzdarip bir projeyi kurtarırken alan güdümlü tasarıma girdim. Herhangi bir domain modeli veyaortak dil olmadan, varolan veri modelini agregalara ve veri erişim nesnelerini repository'lere dönüştürmeye başladık. Bunların yazılıma getirdiği kısıtlamalar sayesinde tutarsızlık sorunlarından kurtulmayı başardık ve sonunda yazılımı production ortamına deoploy edebilir hale geldik.
Taktiksel DDD tasarım ile bu ilk karşılaşma bana projenin tüm diğer yönleri DDD olmasa bile bundan yararlanabileceğimizi kanıtladı. Katıldığım tüm projelerde kullanmak istediğim en sevdiğim DDD yapı taşı değer nesnesidir. Girişleri kolaydır ve özelliklerinize bağlam getirdiği için kodu hemen okumayı ve anlamayı kolaylaştırır. Değişmezlik(Immutability) aynı zamanda karmaşık şeyleri basitleştirme eğilimindedir.
Ayrıca, veri modeli başka şekilde tamamen anemik olsa bile (sadece herhangi bir iş mantığı olmayan getter ve setterlar) veri modellerini agregalar ve repositorylerde gruplandırmaya çalışırım. Bu, verilerin tutarlı tutulmasına yardımcı olur ve aynı varlık farklı mekanizmalar aracılığıyla güncellenirken garip yan etkilerden ve optimistic locking istisnalarından kaçınır.
Domain eventleri kodunuzu ayırmak için yararlıdır, ancak bu iki ucu keskin bir kılıçtır. Eventşere çok fazla güvenirseniz, kodunuzun anlaşılması ve hatalarının ayıklanması zorlaşacaktır, çünkü belirli bir eventin hangi diğer işlemleri tetikleyeceğini veya hangi eventşerin belirli bir işlemin tetiklenmesine neden olduğunu hemen netleştirmez.
Diğer yazılım tasarım desenleri gibi, taktiksel DDD tasarım da, özellikle kurumsal yazılımlar oluştururken karşılaştığınız bir dizi soruna çözümler sunar. Ne kadar elinizin altında olursa, bir yazılım geliştiricisi olarak kariyerinizde kaçınılmaz olarak karşılaştığınız sorunları çözmeniz o kadar kolay olacaktır.
Çeviri için izin veren Petter Holmström'e teşekkürler.
Bonus :
Barış Velioğlu
Domain Driven Design Kimdir?
Kaydol:
Kayıtlar (Atom)







 Türk Ninja IT Dünyası'ndan haberler, röportajlar, makaleler, eğitimler ve video içerikleri sunar.
Türk Ninja IT Dünyası'ndan haberler, röportajlar, makaleler, eğitimler ve video içerikleri sunar.







